Glottal stop (letter)
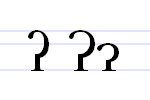
The sign ⟨ʔ⟩ is called "glottal stop," and it is a letter in some extended Latin alphabets of several languages of Canada. It is not part of the basic Latin alphabet or Classical Latin alphabet. Several phonetic transcription schemes, such as the International Phonetic Alphabet (IPA), use versions of glottal stop.
Significance
It typically represents a glottal stop sound.
Similar letters

Since ⟨ʔ⟩ is not in the basic Latin alphabet, typing it can be inconvenient or impossible. Where ⟨ʔ⟩ is not available, it is sometimes replaced by a question mark ⟨?⟩, which is also its official representation in the transcription scheme, SAMPA. In Skwomesh or Squamish, the character may be replaced by the number ⟨7⟩.
Other likely replacements are signs similar to ⟨'⟩ (apostrophe), since they represent glottal stops in other orthographies, such as the sign ʻ (ʻokina) in Hawaiian.
In Unicode, uppercase Latin glottal stop and IPA glottal stop are two different characters (respectively): ⟨Ɂ⟩ and ⟨ʔ⟩. The first is slightly wider than the second. Lowercase and superscript versions are also distinguished:⟨ɂ⟩ ⟨ˀ⟩.
In phonetic transcription as well as in several languages, a single, tall glyph is used in all situations, with no distinction between uppercase and lowercase. However, in the Chipewyan, Dogrib, and Slavey languages, the tall version is only used for the uppercase, and a short version is used for the lowercase.
Usage
Technical transcription
- Americanist phonetic notation and the International Phonetic Alphabet — either ˀ or ʔ.
- Transcription of Australian Aboriginal languages — occasionally ʔ.
- Uralic Phonetic Alphabet — ˀ only.
Vernacular orthographies
- Languages of Canada
- Chipewyan — both Ɂ and ɂ.
- Dogrib — both Ɂ and ɂ.
- Kootenai — ʔ only.
- Musqueam language — ʔ only.
- Nootka — ʔ only.
- Slavey — both Ɂ and ɂ.
- Nitinaht — ʔ only.
- Thompson — ʔ only.
- Lushootseed
- Squamish language, where it is usually represented as ⟨7⟩.
- Romanization of Hebrew
- Biblical — both Ɂ and ɂ. Diaeresis used in Modern Hebrew
Computing codes
In Unicode 1.0, only the tall version and superscript version were included. In version 4.1 (2005), an uppercase character was added, and the existing tall glottal stop was redefined as its lowercase. Finally, in version 5.0 (2006) it was decided to separate the cased and caseless usages, assigning separate characters to each. The IPA character is first from left, while the extended Latin alphabet character is third from left. [1]
| Character | ʔ | ˀ | Ɂ | ɂ | ||||
|---|---|---|---|---|---|---|---|---|
| Unicode name | LATIN LETTER GLOTTAL STOP | MODIFIER LETTER GLOTTAL STOP | LATIN CAPITAL LETTER GLOTTAL STOP | LATIN SMALL LETTER GLOTTAL STOP | ||||
| Character encoding | decimal | hex | decimal | hex | decimal | hex | decimal | hex |
| Unicode | 660 | 0294 | 704 | 02C0 | 577 | 0241 | 578 | 0242 |
| UTF-8 | 202 148 | CA 94 | 203 128 | CB 80 | 201 129 | C9 81 | 201 130 | C9 82 |
| Numeric character reference | ʔ | ʔ | ˀ | ˀ | Ɂ | Ɂ | ɂ | ɂ |
See also
References
- ↑ "Proposal to add LATIN SMALL LETTER GLOTTAL STOP to the UCS" (PDF). 2005-08-10. Retrieved 2013-11-04.
| Wikimedia Commons has media related to Glottal stop letters. |