3D reconstruction from multiple images
3D reconstruction from multiple images is the creation of three-dimensional models from a set of images. It is the reverse process of obtaining 2D images from 3D scenes.
The essence of an image is a projection from a 3D scene onto a 2D plane, during which process the depth is lost. The 3D point corresponding to a specific image point is constrained to be on the line of sight. From a single image, it is impossible to determine which point on this line corresponds to the image point. If two images are available, then the position of a 3D point can be found as the intersection of the two projection rays. This process is referred to as triangulation. The key for this process is the relations between multiple views which convey the information that corresponding sets of points must contain some structure and that this structure is related to the poses and the calibration of the camera.
In recent decades, there is an important demand for 3D content for computer graphics, virtual reality and communication, triggering a change in emphasis for the requirements. Many existing systems for constructing 3D models are built around specialized hardware (e.g. stereo rigs) resulting in a high cost, which cannot satisfy the requirement of its new applications. This gap stimulates the use of digital imaging facilities (like a camera). Moore's law also tells us that more work can be done in software. An early method was proposed by Tomasi and Kanade.[1] They used an affine factorization approach to extract 3D from images sequences. However, the assumption of orthographic projection is a significant limitation of this system.
Processing
The task of converting multiple 2D images into 3D model consists of a series of processing steps:
Camera calibration consists of intrinsic and extrinsic parameters, without which at some level no arrangement of algorithms can work. The dotted line between Calibration and Depth determination represents that the camera calibration is usually required for determining depth.
Depth determination serves as the most challenging part in the whole process, as it calculates the 3D component missing from any given image – depth. The correspondence problem, finding matches between two images so the position of the matched elements can then be triangulated in 3D space is the key issue here.
Once you have the multiple depth maps you have to combine them to create a final mesh by calculating depth and projecting out of the camera – registration. Camera calibration will be used to identify where the many meshes created by depth maps can be combined together to develop a larger one, providing more than one view for observation.
By the stage of Material Application you have a complete 3D mesh, which may be the final goal, but usually you will want to apply the color from the original photographs to the mesh. This can range from projecting the images onto the mesh randomly, through approaches of combining the textures for super resolution and finally to segmenting the mesh by material, such as specular and diffuse properties.
Mathematical description of reconstruction
Given a group of 3D points viewed by N cameras with matrices . Define be the homogeneous coordinates of the projection of the point onto the camera. The reconstruction problem can be changed to: given the group of pixel coordinates , find the corresponding set of camera matrices and the scene structure such that







- (1)
Generally, without further restrictions, we will obtain a projective reconstruction.[2][3] If and satisfy (1), and will satisfy (1) with any 4 × 4 nonsingular matrix T.


A projective reconstruction can be calculated by points correspondences only, without any a-priori information.
Autocalibration
Autocalibration or self-calibration is the classical approach, in which camera motion and parameters are recovered first, using rigidity, then structure is readily calculated. Two methods implementing this idea are presented as follows:
Kruppa equations
With a minimum of three displacements, we can obtain the internal parameters of the camera using a system of polynomial equations due to Kruppa,[4] which are derived from a geometric interpretation of the rigidity constraint.[5][6]
The matrix is unknown in the Kruppa equations, named Kruppa coefficients matrix. With K and by the method of Cholesky factorization one can obtain the intrinsic parameters easily:


Recently Hartley [7] proposed a simpler form. Let be written as , where


Then the Kruppa equations are rewritten (the derivation can be found in [8])
Mendonça and Cipolla
This method is based on the use of rigidity constraint. Design a cost function, which considers the intrinsic parameters as arguments and the fundamental matrices as parameters. is defined as the fundamental matrix, and as intrinsic parameters matrices.



Stratification
Recently, new methods based on the concept of stratification have been proposed. Starting from a projective structure, which can be calculated from correspondences only, upgrade this projective reconstruction to a Euclidean reconstruction, by making use of all the available constraints. With this idea the problem can be stratified into different sections: according to the amount of constraints available, it can be analyzed at a different level, projective, affine or Euclidean.
The stratification of 3D geometry
Usually, the world is perceived as a 3D Euclidean space. In some cases, it is not possible to use the full Euclidean structure of 3D space. The simplest being projective, then the affine geometry which forms the intermediate layers and finally Euclidean geometry. The concept of stratification is closely related to the series of transformations on geometric entities: in the projective stratum is a series of projective transformations (a homography), in the affine stratum is a series of affine transformations, and in Euclidean stratum is a series of Euclidean transformations.
Suppose that a fixed scene is captured by two or more perspective cameras and the correspondences between visible points in different images are already given. However, in practice, the matching is an essential and extremely challenging issue in computer vision. Here, we suppose that 3D points are observed by cameras with projection matrices Neither the positions of point nor the projection of camera are known. Only the projections of the point in the image are known.





Projective reconstruction
Simple counting indicates we have independent measurements and only unknowns, so the problem is supposed to be soluble with enough points and images. The equations in homogeneous coordinates can be represented:


- (2)

So we can apply a nonsingular 4 × 4 transformation H to projections → and world points →. Hence, without further constraints, reconstruction is only an unknown projective deformation of the 3D world.



Affine Reconstruction
See affine space for more detailed information about computing the location of the plane at infinity . The simplest way is to exploit prior knowledge, for example the information that lines in the scene are parallel or that a point is the one thirds between two others.

We can also use prior constraints on the camera motion. By analyzing different images of the same point can obtain a line in the direction of motion. The intersection of several lines is the point at infinity in the motion direction, and one constraint on the affine structure.
Euclidean Reconstruction
By mapping the projective reconstruction to one that satisfies a group of redundant Euclidean constraints,we can find a projective transformation H in equation (2).The equations are highly nonlinear and a good initial guess for the structure is required. This can be obtained by assuming a linear projection - parallel projection, which also allows easy reconstruction by SVD decomposition.[9]
Algebraic vs geometric error
Inevitably, measured data (i.e., image or world point positions) is noisy and the noise comes from many sources. To reduce the effect of noise, we usually use more equations than necessary and solve with least squares.
For example, in a typical null-space problem formulation Ax = 0 (like the DLT algorithm), the square of the residual ||Ax|| is being minimized with the least squares method.
In general, if ||Ax|| can be considered as a distance between the geometrical entities (points, lines, planes, etc.), then what is being minimized is a geometric error, otherwise (when the error lacks a good geometrical interpretation) it is called an algebraic error.
Therefore, compared with algebraic error, we prefer to minimize a geometric error for the reasons listed:
1). the quantity being minimized has a meaning.
2). the solution is more stable.
3). the solution is constant under Euclidean transforms.
All the linear algorithms (DLT and others) we have seen so far minimize an algebraic error. Actually, there is no justification in minimizing an algebraic error apart from the ease of implementation, as it results in a linear problem. The minimization of a geometric error is often a non-linear problem, that admit only iterative solutions and requires a starting point.
Usually, linear solution based on algebraic residuals serves as a starting point for a non-linear minimization of a geometric cost function, which provides the solution a final “polish”.[10]
3D reconstruction of Medical Images
Motivation & applications
The 2-D imaging has problems of anatomy overlapping with each other and don’t disclose the abnormalities. The 3-D imaging can be used for both diagnostic and therapeutic purposes.
3-D models are used for planning the operation, morphometric studies and has more reliability in orthopedics.
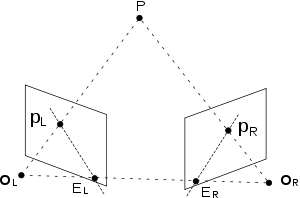
Problem statement & Basics
To reconstruct 3-D images from 2-D images taken by a camera at multiple angles. Lateral view of the bone Medical imaging techniques like CT scan and MRI are expensive. Though CT scan is accurate, it induces high radiation dose which is a risk for patients with certain diseases. Methods based on MRI are not accurate. Since we are exposed to powerful magnetic field, this method is not suitable for patients with ferromagnetic metallic implants. Both the methods can be done only when in lying position where the global structure of the bone changes. So, we discuss the following methods which can be performed while standing and require low radiation dose.
Though these techniques are 3-D imaging, the region of interest is restricted to a slice, data is acquired to form a time sequence.
Efficient Algorithms
1) Stereo Corresponding Point Based Technique
This method is simple and implemented by identifying the points manually in multi-view radiographs. The first step is to extract the corresponding points in two x-ray images and second step is the 3D reconstruction with algorithms like Discrete Linear Transform [35]. Using DLT, the reconstruction is done only where there are SCPs. By increasing the number of points, the results improve [36]but it is time consuming. This method has low accuracy because of low reproducibility and time consumption. This method is dependent on the skill of the operator. This method is not suitable for bony structures with continuous shape. This method is generally used as an initial solution for other methods[37]. anterier view of the bone
2) Non-Stereo corresponding contour method(NCSS)
This method uses X-ray images for 3D Reconstruction and to develop 3D models with low dose radiations in weight bearing positions.
In NSCC algorithm, the preliminary step is calculation of an initial solution. Firstly anatomical regions from the generic object are defined. Secondly, manual 2D contours identification on the radiographs is performed. From each radiograph 2D contours are generated using the 3D initial solution object. 3D contours of the initial object surface are projected onto their associated radiograph [37]. The 2D association performed between these 2 set points is based on point-to-point distances and contours derivations developing a correspondence between the 2D contours and the 3D contours. Next step is optimization of the initial solution. Lastly deformation of the optimized solution is done by applying Kriging algorithm to the optimized solution [38]. Finally, by iterating the final step until the distance between two set points is superior to a given precision value the reconstructed object is obtained.
The advantage of this method is they can be used for bony structures with continuous shape and it also reduced human intervention but they are time consuming. posterier view of the bone
3) Surface Rendering technique
Surface Rendering technique visualizes a 3D object as a set of surfaces called iso-surfaces. Each surface has points with same intensity (called iso-value). It is used when we want to see the separated structures e.g. skull from slices of head, blood vessel system from slices of body etc. This technique is used mostly for high contrast data. Two main methods for reconstructing are:
- Contour based reconstruction: Iso-contours are attached to form iso-surfaces[39]
- Voxel based reconstruction: Voxels having same intensity values are used to form iso-surfaces. One of the best algorithms is Marching Cubes [39] *Some similar algorithms as Marching Tetrahedrons, Deviding Cubes [39] can be considered.
Other methods which can be used for 3d reconstruction are
Other proposed or developed techniques include Statistical Shape Model Based Methods, Parametric Methods, Hybrid methods.
See also
- 3D modeling
- 3D reconstruction
- 3D photography
- 2D to 3D conversion
- 3D data acquisition and object reconstruction
- Epipolar geometry
- Camera resectioning
- Computer stereo vision
- Stereophotogrammetry
- Comparison of photogrammetry software
References
- ↑ C. Tomasi and T. Kanade, “Shape and motion from image streams under orthography: A factorization approach”, International Journal of Computer Vision, 9(2):137-154, 1992.
- ↑ R. Mohr and E. Arbogast. It can be done without camera calibration. Pattern Recognition Letters, 12:39-43, 1991.
- ↑ O. Faugeras. What can be seen in three dimensions with an uncalibrated stereo rig? In Proceedings of the European Conference on Computer Vision, pages 563-578, Santa Margherita L., 1992.
- ↑ E. Kruppa. Zur Ermittlung eines Objektes aus zwei Perspektiven mit innerer Orientierung. Sitz.-Ber.Akad.Wiss., Wien, math. naturw. Kl., Abt. IIa., 122:1939-1948, 1913.
- ↑ S. J. Maybank and O. Faugeras. A theory of self-calibration of a moving camera. International Journal of Computer Vision, 8(2):123-151, 1992.
- ↑ O. Faugeras and S. Maybank. Motion from point matches: multiplicity of solutions. International Journal of Computer Vision, 4(3):225-246, June 1990.
- ↑ R. I. Hartley. Kruppa's equations derived from the fundamental matrix. IEEE Transactions on Pattern Analysis and Machine Intelligence, 19(2):133-135, February 1997.
- ↑ R. I. Hartley. Kruppa's equations derived from the fundamental matrix. IEEE Transactions on Pattern Analysis and Machine Intelligence, 19(2):133-135, February 1997.
- ↑ C. Tomasi and T. Kanade. Shape and motion from image streams under orthography: A factorization method. International Journal of Computer Vision, 9(2):137-154, 1992.
- ↑ R. Hartley and A. Zisserman. Multiple view geometry in computer vision. Cambridge University Press, 2nd edition, 2003.
Further reading
External links
| Look up 3d reconstruction from multiple images in Wiktionary, the free dictionary. |
- 3D Reconstruction from Multiple Images - discusses methods to extract 3D models from plain images.
- Visual 3D Modeling from Images and Videos - a tech-report describes the theory, practice and tricks on 3D reconstruction from images and videos.