Graph database
In computing, a graph database is a database that uses graph structures for semantic queries with nodes, edges and properties to represent and store data. A key concept of the system is the graph (or edge or relationship), which directly relates data items in the store. The relationships allow data in the store to be linked together directly, and in many cases retrieved with a single operation.
This contrasts with conventional relational databases, where links between data are stored in the data itself, and queries search for this data within the store and use the JOIN concept to collect the related data. Graph databases, by design, allow simple and rapid retrieval of complex hierarchical structures that are difficult to model in relational systems. Graph databases are similar to 1970s network-model databases in that both represent general graphs, but network-model databases operate at a lower level of abstraction[1] and lack easy traversal over a chain of edges.[2]
The underlying storage mechanism of graph database products varies. Some depend on a relational engine and store the graph data in a table while others use a key-value store or document-oriented database for storage, making them inherently NoSQL structures. Most graph databases based on non-relational storage engines also add the concept of tags or properties, which are essentially relationships lacking a pointer to another document. This allows data elements to be categorized for easy retrieval en masse.
Retrieving data from a graph database requires a query language other than SQL, which was designed for relational databases and does not elegantly handle traversing a graph. As of 2016, no single graph query language has been universally adopted in the same fashion as SQL was for relational databases, and there are a wide variety of systems - most often tightly tied to a particular product. Some standardization efforts have taken place, leading to multi-vendor query languages like Gremlin, SPARQL, and Cypher. In addition to having query language interfaces, some graph databases are accessed through APIs.
Description
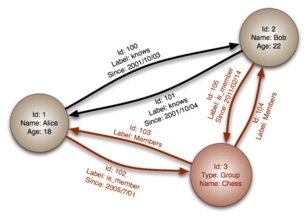
Graph databases are based on graph theory. Graph databases employ nodes, edges and properties.
- Nodes represent entities such as people, businesses, accounts, or any other item you might want to keep track of. They are roughly the equivalent of the record, relation or row in a relational database, or the document in a document database.
- Edges, also known as graphs or relationships, are the lines that connect nodes to other nodes; they represent the relationship between them. Meaningful patterns emerge when examining the connections and interconnections of nodes, properties, and edges. Edges are the key concept in graph databases, representing an abstraction that is not directly implemented in other systems.
- Properties are pertinent information that relate to nodes. For instance, if Wikipedia were one of the nodes, one might have it tied to properties such as website, reference material, or word that starts with the letter w, depending on which aspects of Wikipedia are pertinent to the particular database.
The relational model gathers data together using information in the data itself. For instance, one might look for all the "users" whose phone number contains the area code "311". This would be accomplished by searching selected datastores, or tables, looking in the selected phone number fields for the string "311". This can be a time consuming process in large tables, so relational databases offer the concept of an index which allows data like this to be stored in a smaller sub-table, containing only the selected data and a unique key (or primary key) of the record it is part of. If the phone numbers are indexed, the same search would take place in the smaller index table, gathering the keys of matching records, and then looking in the main data table for the records with those keys. Generally, the tables are physically stored so that lookups on these keys are rapid.[3]
Relational databases do not inherently contain the idea of fixed relationships between records. Instead, related data is linked to each other by storing one record's unique key in another record's data. For instance, a table containing email addresses for users might hold a data item called userpk, which contains the primary key of the user record it is associated with. In order to link users and their email addresses, the system first looks up the selected user records primary keys, looks for those keys in the userpk column in the email table (or more likely, an index of them), extracts the email data, and then links the user and email records to make composite records containing all the selected data. This operation, known as a join, can be computationally expensive. Depending on the complexity of the query, the number of joins, and the indexing of the various keys, the system may have to search through multiple tables and indexes, gather up lots of information, and then sort it all to match it together.[3]
In contrast, graph databases directly store the relationships between records. Instead of an email address being found by looking up its user's key in the userpk column, the user record has a pointer directly to the email address record. That is, having selected a user, the pointer can be followed directly to the email records, there is no need to search the email table to find the matching records. This can eliminate the costly join operations. For instance, if one searches for all of the email addresses for users in area code "311", the engine would first perform a conventional search to find the users in "311", but then retrieve the email addresses by following the links found in those records. A relational database would first find all the users in "311", extract a list of the pk's, perform another search for any records in the email table with those pk's, and link the matching records together. For these types of common operations, a graph database (in theory at least) is significantly faster.[3]
The true value of the graph approach becomes evident when one performs searches that are more than one level deep. For instance, consider a search for users who have "subscribers" (a table linking users to other users) in the "311" area code. In this case a relational database has to first look for all the users with an area code in "311", then look in the subscribers table for any of those users, and then finally look in the users table to retrieve the matching users. In comparison, a graph database would look for all the users in "311", then follow the back-links through the subscriber relationship to find the subscriber users. This avoids several searches, lookups and the memory involved in holding all of the temporary data from multiple records needed to construct the output. Technically, this sort of lookup is completed in O(log(n)) + O(1) time, that is, roughly relative to the logarithm of the size of the data. In comparison, the relational version would be multiple O(log(n)) lookups plus additional time to join all the data.[3]
The relative advantage of graph retrieval grows with the complexity of the query. For instance, one might want to know "that movie about submarines with the actor who was in that movie with that other actor that played the lead in Gone With the Wind". This first requires the system to find the actors in Gone With the Wind, find all the movies they were in, find all the actors in all of those movies who were not the lead in Gone With the Wind, and then find all of the movies they were in, finally filtering that list to those with descriptions containing "submarine". In a relational database this will require several separate searches through the movies and actors tables, doing another search on submarine movies, finding all the actors in those movies, and the comparing the (large) collected results. In comparison, the graph database would simply walk from Gone With the Wind to Clark Gable, gather the links to the movies he has been in, gather the links out of those movies to other actors, and then follow the links out of those actors back to the list of movies. The resulting list of movies can then be searched for "submarine". All of this can be accomplished using a single search.[4]
Properties add another layer of abstraction to this structure that also improves many common queries. Properties are essentially labels that can be applied to any record, or in some cases, edges as well. For instance, one might label Clark Gable as "actor", which would then allow the system to quickly find all the records that are actors, as opposed to director or camera operator. If labels on edges are allowed, one could also label the relationship between Gone With the Wind and Clark Gable as "lead", and by performing a search on people that are "lead" "actor" in the movie Gone With the Wind, the database would produce Vivien Leigh, Olivia de Havilland and Clark Gable. The equivalent SQL query would have to rely on additional data in the table linking people and movies, adding more complexity to the query syntax. These sorts of labels may improve search performance under certain circumstances, but are generally more useful in providing additional semantic data for end users.[4]
Relational databases are very well suited to flat data layouts, where relationships between data is one or two levels deep. For instance, an accounting database might need to look up all the line items for all the invoices for a given customer, a three-join query. Graph databases are aimed at datasets that contain many more links. They are especially well suited to social networking systems, where the "friends" relationship is essentially unbounded. These properties make graph databases naturally suited to types of searches that are increasingly common in online systems, and in big data environments. For this reason, graph databases are becoming very popular for large online systems like Facebook, Google, Twitter and similar systems with deep links between records.
Properties
Compared with relational databases, graph databases are often faster for associative data sets and map more directly to the structure of object-oriented applications. They can scale more naturally to large data sets as they do not typically require expensive join operations. As they depend less on a rigid schema, they are more suitable to manage ad hoc and changing data with evolving schemas. Conversely, relational databases are typically faster at performing the same operation on large numbers of data elements.
Graph databases are a powerful tool for graph-like queries, for example computing the shortest path between two nodes in the graph. Other graph-like queries can be performed over a graph database in a natural way (for example graph's diameter computations or community detection).
History
In the pre-history of graph databases, in the mid-1960s Navigational databases such as IBM's IMS supported tree-like structures in its hierarchical model, but the strict tree structure could be circumvented with virtual records.[5][6]
Graph structures could be represented in network model databases from the late 1960s. CODASYL, which had defined COBOL in 1959, defined the Network Database Language in 1969.
Labeled graphs could be represented in graph databases from the mid-1980s, such as the Logical Data Model.[1][7]
A number of improvements to graph databases appeared in the early 1990s, accelerating in the late 1990s with endeavors to index web pages.
In the mid-late 2000s, commercial ACID graph databases such as Neo4j and Oracle Spatial and Graph became available.
In the 2010s, commercial ACID graph databases that could be scaled horizontally became available. SAP HANA additionally brought in-memory and columnar technologies to graph databases.[8] Also in the 2010s, Multi-model databases that supported graph models (in addition to other models such as relational database or Document-oriented database) became available, such as OrientDB, ArangoDB, and MarkLogic (starting with its 7.0 version). During this time, graph databases of various types have become particularly popular with social network analysis with the advent of social media companies.
List of graph databases
The following is a list of notable graph databases:
| Name | Version | License | Language | Description |
|---|---|---|---|---|
| AllegroGraph | 5.1 (May 2015) | Proprietary. Clients: Eclipse Public License v1. | C#, C, Common Lisp, Java, Python | An RDF and graph database. |
| ArangoDB | 3.1.3 (December 2016) | Apache 2 | C++ , Javascript | The most popular NoSQL database available that has an open source license.[9] |
| Blazegraph | 2.1 (April 2016) | GPLv2, evaluation license, or commercial license. | Java | A RDF/graph database capable of clustered deployment and GPU (in the commercial version). Blazegraph supports high availability (HA) mode, embedded mode, single server mode. Supports the Blueprints and SPARQL.[10][11] |
| Cayley | 0.6.0 (September 2016) | Apache 2 | Go | An open-source graph database.[12] |
| DataStax Enterprise Graph | v5.0.2 (August 2016) | Proprietary | Java | A distributed, real-time, scalable graph database inspired by Titan. Supports Tinkerpop and integrates with Cassandra.[13] |
| DEX/Sparksee[14] | 5.2.0 (2015) | Evaluation, research or development use is free; commercial use is not free | C++ | A high-performance and scalable graph database management system from Sparsity Technologies. Its main characteristics is its query performance for the retrieval & exploration of large networks. Sparksee offers bindings for Java, C++, C#, Python and Objective-C. Sparksee 5 mobile is the first graph database for mobile devices. |
| InfiniteGraph | 3.0 (January 2013) | Proprietary | Java | A distributed and cloud-enabled commercial product. |
| MarkLogic | 8.0.4 (2015) | Proprietary, free developer version | Java, JavaScript, XQuery | Multi-model NoSQL database that stores documents (JSON and XML) and semantic graph data (RDF triples). MarkLogic also has a built-in search engine and a full-list of enterprise features such as ACID transactions, high availability and disaster recovery, certified security, and scalability and elasticity. |
| Neo4j | 3.0.6 (September 2016) | GPLv3 Community Edition. Commercial & AGPLv3 options for enterprise and advanced editions | Java, .NET, JavaScript, Python | A highly scalable open source graph database that supports ACID, has high-availability clustering for enterprise deployments, and comes with a web-based administration tool that includes full transaction support and visual node-link graph explorer. Neo4j is accessible from most programming languages using its built-in REST web API interface, as well as a proprietary Bolt protocol with official drivers. Neo4j is the most popular graph database in use as of March 2016.[15] |
| OpenCog | AGPL | C++, Scheme, Python | Includes a satisfiability modulo theories solver and a unified rule engine for performing both crisp (boolean) logic and probabilistic reasoning. Backed onto Postgres. | |
| Ontotext GraphDB | 7 | GraphDB Free is free. GraphDB Standard and GraphDB Enterprise are commercially licensed. | Java | A graph database engine, based fully on Semantic Web standards from W3C: RDF, RDFS, OWL, SPARQL. GraphDB Free is a database engine for small projects. GraphDB Standard is robust standalone database engine. GraphDB Enterprise is a clustered version which offers horizontal scalability and failover support and other enterprise features. |
| OpenLink Virtuoso | 7.2.4 (April 2016) | GPLv2 for Open Source Edition. Proprietary for Enterprise Edition. | C, C++ | A hybrid database server handling RDF and other graph data, RDB/SQL data, XML data, filesystem documents/objects, and free text. May be deployed as a local embedded instance (as used in the NEPOMUK Semantic Desktop), a single-instance network server, or a shared-nothing elastic-cluster multiple-instance networked server.[16] |
| Oracle Spatial and Graph (part of Oracle Database) | 12.1.0.2 (2014) | Proprietary | Java, PL/SQL | 1) RDF Semantic Graph: comprehensive W3C RDF graph management in Oracle Database with native reasoning and triple-level label security. 2) Network Data Model property graph: for physical/logical networks with persistent storage and a Java API for in-memory graph analytics. |
| OrientDB | 2.2.0 (May 2016) | Community Edition is Apache 2, Enterprise Edition is commercial | Java | OrientDB is an open source 2nd Generation Distributed Graph Database with the flexibility of Documents in one product (i.e., it is both a graph database and a document nosql database at the same time.) It has an open source commercial friendly (Apache 2) license. It is a highly scalable graph database with full ACID support. It has a multi-master replication and sharding. Supports schema-less, schema-full and schema-mixed modes. Has a strong security profiling system based on user and roles. Supports a query language that is so similar to SQL which is friendly to those coming from a SQL and relational database background decreasing the learning curve needed. It has HTTP REST + JSON API. |
| Profium Sense | 6.2 (November 2016) | Proprietary | Java | Profium Sense is a native in-memory graph database. Profium Sense contains a rule engine that is optimized for information streams that require continuous inferencing on-the-fly. Profium architecture is based on an in-memory database with ACID transaction support and supports distributed high-availability deployment. Profium Sense supports open standards such as RDF and SPARQL. |
| SAP HANA | SPS12 Revision 120 | Proprietary | C, C++, Java, JavaScript & SQL like language | In-memory ACID transaction supported property graph[17] |
| Sqrrl Enterprise | 2.0 (February 2015) | Proprietary | Java | Distributed, real-time graph database featuring cell-level security and mass-scalability.[18] |
| Stardog | 3.1.5 (July 2015) | Proprietary | Java | Fast, scalable, pure Java semantic graph database. |
| Teradata Aster | v7 (2016) | Proprietary | Java, SQL, Python, C++, R | A high performance, multi-purpose, highly scalable and extensible MPP database incorporating patented engines supporting native SQL, MapReduce and Graph data storage and manipulation. An extensive set of analytical function libraries and data visualization capabilities are also provided.[19] |
APIs and graph query-programming languages
- Cypher – a declarative graph query language for Neo4j that enables ad hoc and programmatic (SQL-like) access to the graph. Spec opened up as openCypher project.[20]
- GraphQL – Facebook query language for any backend service
- Gremlin – an open-source graph programming language that works over various graph database systems. Part of the Apache TinkerPop project [21]
- SPARQL – a query language for databases, able to retrieve and manipulate data stored in Resource Description Framework format.
See also
References
- 1 2 Angles, Renzo; Gutierrez, Claudio (1 Feb 2008). "Survey of graph database models" (PDF). ACM Computing Surveys. Association for Computing Machinery. 40 (1). doi:10.1145/1322432.1322433. Retrieved 28 May 2016.
network models [...] lack a good abstraction level: it is difficult to separate the db-model from the actual implementation
- ↑ Silberschatz, Avi (28 January 2010). Database System Concepts, Sixth Edition (PDF). McGraw-Hill. p. D-29. ISBN 0-07-352332-1.
- 1 2 3 4 "From Relational to Graph Databases". Neo4j.
- 1 2 "Examples where Graph databases shine: Neo4j edition", ZeroTurnaround
- ↑ Silberschatz, Avi (28 January 2010). Database System Concepts, Sixth Edition (PDF). McGraw-Hill. p. E-20. ISBN 0-07-352332-1.
- ↑ Parker, Lorraine. "IMS Notes". vcu.edu. Retrieved 31 May 2016.
- ↑ Kuper, Gabriel M (1985). The Logical Data Model: A New Approach to Database Logic (PDF) (Ph.D.). Docket STAN-CS-85-1069. Retrieved 31 May 2016.
- ↑ "SAP Announces New Capabilities in the Cloud with HANA". 2014-10-22. Retrieved 2016-07-07.
- ↑ Adam Fowler (24 February 2015). NoSQL For Dummies. John Wiley & Sons. pp. 298–. ISBN 978-1-118-90574-6.
- ↑ Vaughan, Jack (25 January 2016). "Beyond gaming, GPU technology takes on graphs, machine learning". techtarget.com. TechTarget. Retrieved 30 August 2016.
- ↑ Yegulalp, Serdar (26 September 2016). "Faster with GPUs: 5 turbocharged databases". infoworld.com. InfoWorld. Retrieved 29 September 2016.
- ↑ "Google Releases Cayley Open-Source Graph Database". eweek.com. 2014-11-13. Retrieved 2016-11-13.
- ↑ Woodie, Alex (21 June 2016). "Beyond Titan: The Evolution of DataStax's New Graph Database". datanami.com. Datanami. Retrieved 29 August 2016.
- ↑ http://sparsity-technologies.com#sparksee
- ↑ DB-Engines Ranking of Graph DBMS
- ↑ OpenLink Software. "Clustering Deployment Architecture Diagrams for Virtuoso (Release 6 and later, Commercial Edition only)". Virtuoso Open-Source Wiki. OpenLink Software. Retrieved 2014-05-01.
- ↑ Rudolf, Michael; Paradies, Marcus; Bornhövd, Christof; Lehner, Wolfgang. The Graph Story of the SAP HANA Database (PDF). Lecture Notes: Datenbanksysteme für Business, Technologie und Web (BTW).
- ↑ Vanian, Jonathan (18 February 2015). "NSA-linked Sqrrl eyes cyber security and lands $7M in funding". gigaom.com. Gigaom. Retrieved 29 August 2016.
- ↑ Woodie, Alex (23 October 2015). "The Art of Analytics, Or What the Green-Haired People Can Teach Us". datanami.com. Datanami. Retrieved 29 August 2016.
- ↑ Svensson, Johan (5 July 2016). "Guest View: Relational vs. graph databases: Which to use and when? - See more at: http://sdtimes.com/guest-view-relational-vs-graph-databases-use/#sthash.mj23RKDE.dpuf". sdtimes.com. BZ Media. Retrieved 30 August 2016. External link in
|title=(help) - ↑ TinkerPop, Apache. "Apache TinkerPop". tinkerpop.apache.org. Retrieved 2016-11-02.