Hierarchical temporal memory
Hierarchical temporal memory (HTM) is an unsupervised to semi-supervised online machine learning model developed by Jeff Hawkins and Dileep George of Numenta, Inc. that models some of the structural and algorithmic properties of the neocortex. HTM is a biomimetic model based on the memory-prediction theory of brain function described by Jeff Hawkins in his book On Intelligence. HTM is a method for discovering and inferring the high-level causes of observed input patterns and sequences, thus building an increasingly complex model of the world.
Jeff Hawkins states that HTM does not present any new idea or theory, but combines existing ideas to mimic the neocortex with a simple design that provides a large range of capabilities. HTM combines and extends approaches used in Sparse distributed memory, Bayesian networks, spatial and temporal clustering algorithms, while using a tree-shaped hierarchy of nodes that is common in neural networks.
HTM structure and algorithms
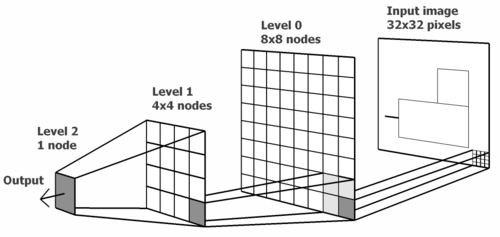
A typical HTM network is a tree-shaped hierarchy of levels that are composed of smaller elements called nodes or columns. A single level in the hierarchy is also called a region. Higher hierarchy levels often have fewer nodes and therefore less spatial resolvability. Higher hierarchy levels can reuse patterns learned at the lower levels by combining them to memorize more complex patterns.
Each HTM node has the same basic functionality. In learning and inference modes, sensory data comes into the bottom level nodes. In generation mode, the bottom level nodes output the generated pattern of a given category. The top level usually has a single node that stores the most general categories (concepts) which determine, or are determined by, smaller concepts in the lower levels which are more restricted in time and space. When in inference mode, a node in each level interprets information coming in from its child nodes in the lower level as probabilities of the categories it has in memory.
Each HTM region learns by identifying and memorizing spatial patterns - combinations of input bits that often occur at the same time. It then identifies temporal sequences of spatial patterns that are likely to occur one after another.
Zeta 1: first generation node algorithms
During training, a node receives a temporal sequence of spatial patterns as its input. The learning process consists of two stages:
- Spatial pooling identifies frequently observed patterns and memorizes them as coincidences. Patterns that are significantly similar to each other are treated as the same coincidence. A large number of possible input patterns are reduced to a manageable number of known coincidences.
- Temporal pooling partitions coincidences that are likely to follow each other in the training sequence into temporal groups. Each group of patterns represents a "cause" of the input pattern (or "name" in On Intelligence).
During inference (recognition), the node calculates the set of probabilities that a pattern belongs to each known coincidence. Then it calculates the probabilities that the input represents each temporal group. The set of probabilities assigned to the groups is called a node's "belief" about the input pattern. (In a simplified implementation, node's belief consists of only one winning group). This belief is the result of the inference that is passed to one or more "parent" nodes in the next higher level of the hierarchy.
"Unexpected" patterns to the node do not have a dominant probability of belonging to any one temporal group, but have nearly equal probabilities of belonging to several of the groups. If sequences of patterns are similar to the training sequences, then the assigned probabilities to the groups will not change as often as patterns are received. The output of the node will not change as much, and a resolution in time is lost.
In a more general scheme, the node's belief can be sent to the input of any node(s) in any level(s), but the connections between the nodes are still fixed. The higher-level node combines this output with the output from other child nodes thus forming its own input pattern.
Since resolution in space and time is lost in each node as described above, beliefs formed by higher-level nodes represent an even larger range of space and time. This is meant to reflect the organization of the physical world as it is perceived by human brain. Larger concepts (e.g. causes, actions and objects) are perceived to change more slowly and consist of smaller concepts that change more quickly. Jeff Hawkins postulates that brains evolved this type of hierarchy to match, predict, and affect the organization of the external world.
More details about the functioning of Zeta 1 HTM can be found in Numenta's old documentation.[1]
Cortical learning algorithms
The new generation of HTM learning algorithms relies on fixed-sparsity distributed representations.[2][3] It models cortical columns that tend to inhibit neighboring columns in the neocortex thus creating a sparse activation of columns. A region creates a sparse representation from its input, so that a fixed percentage of columns are active at any one time.
Each HTM region consists of a number of highly interconnected cortical columns. A region is similar to layer III of the neocortex. A cortical column is understood as a group of cells that have the same receptive field. Each column has a number of cells that are able to remember several previous states. A cell can be in one of three states: active, inactive and predictive state.
Spatial pooling: The receptive field of each column is a fixed number of inputs that are randomly selected from a much larger number of node inputs. Based on the input pattern, some columns will receive more active input values. Spatial pooling selects a relatively constant number of the most active columns and inactivates (inhibits) other columns in the vicinity of the active ones. Similar input patterns tend to activate a stable set of columns. The amount of memory used by each region can be increased to learn more complex spatial patterns or decreased to learn simpler patterns.
Representing the input in the context of previous inputs: If one or more cells in the active column are in the predictive state (see below), they will be the only cells to become active in the current time step. If none of the cells in the active column are in the predictive state (during the initial time step or when the activation of this column was not expected), all cells are made active.
Predicting future inputs and temporal pooling: When a cell becomes active, it gradually forms connections to nearby cells that tend to be active during several previous time steps. Thus a cell learns to recognize a known sequence by checking whether the connected cells are active. If a large number of connected cells are active, this cell switches to the predictive state in anticipation of one of the few next inputs of the sequence. The output of a region includes columns in both active and predictive states. Thus columns are active over longer periods of time, which leads to greater temporal stability seen by the parent region.
Cortical learning algorithms are able to learn continuously from each new input pattern, therefore no separate inference mode is necessary. During inferenhce, HTM tries to match the stream of inputs to fragments of previously learned sequences. This allows each HTM region to be constantly predicting the likely continuation of the recognized sequences. The index of the predicted sequence is the output of the region. Since predictions tend to change less frequently than the input patterns, this leads to increasing temporal stability of the output in higher hierarchy levels. Prediction also helps to fill in missing patterns in the sequence and to interpret ambiguous data by biasing the system to infer what it predicted.
Cortical learning algorithms are currently being offered as commercial SaaS by Numenta (such as Grok[4]).
The following question was posed to Jeff Hawkins September 2011 with regard to Cortical learning algorithms: "How do you know if the changes you are making to the model are good or not?" To which Jeff's response was "There are two categories for the answer: one is to look at neuroscience, and the other is methods for machine intelligence. In the neuroscience realm there are many predictions that we can make, and those can be tested. If our theories explain a vast array of neuroscience observations then it tells us that we’re on the right track. In the machine learning world they don’t care about that, only how well it works on practical problems. In our case that remains to be seen. To the extent you can solve a problem that no one was able to solve before, people will take notice."[5]
Comparing HTM and neocortex
Comparing high-level structures and functionality of neocortex with HTM is most appropriate. HTM attempts to implement the functionality that is characteristic of a hierarchically related group of cortical regions in the neocortex. A region of the neocortex corresponds to one or more levels in the HTM hierarchy, while the hippocampus is remotely similar to the highest HTM level. A single HTM node may represent a group of cortical columns within a certain region.
Although it is primarily a functional model, several attempts have been made to relate the algorithms of the HTM with the structure of neuronal connections in the layers of neocortex.[6][7] The neocortex is organized in vertical columns of 6 horizontal layers. The 6 layers of cells in the neocortex should not be confused with levels in an HTM hierarchy.
HTM nodes attempt to model a portion of cortical columns (80 to 100 neurons) with approximately 20 HTM "cells" per column. HTMs model only layers 2 and 3 to detect spatial and temporal features of the input with 1 cell per column in layer 2 for spatial "pooling", and 1 to 2 dozen per column in layer 3 for temporal pooling. A key to HTMs and the cortex's is their ability to deal with noise and variation in the input which is a result of using a "sparse distributive representation" where only about 2% of the columns are active at any given time.
An HTM attempts to model a portion of the cortex's learning and plasticity as described above. Differences between HTMs and neurons include:[8]
- strictly binary signals and synapses
- no direct inhibition of synapses or dendrites (but simulated indirectly)
- currently only models layers 2/3 and 4 (no 5 or 6)
- no "motor" control (layer 5)
- no feed-back between regions (layer 6 of high to layer 1 of low)
Sparse distributed representations
Integrating memory component with neural networks has a long history dating back to early research in distributed representations[9][10] and self-organizing maps. For example, in sparse distributed memory (SDM), the patterns encoded by neural networks are used as memory addresses for content-addressable memory, with "neurons" essentially serving as address encoders and decoders.[11][12]
Computers store information in "dense" representations such as a 32 bit word where all combinations of 1s and 0s are possible. By contrast, brains use sparse distributed representations (SDR).[13] The human neocortex has roughly 100 billion neurons, but at any given time only a small percent are active. The activity of neurons are like bits in a computer, and therefore the representation is sparse. Similarly to SDM developed by NASA in the 80s[11] and vector space models used in Latent semantic analysis, HTM also uses Sparse Distributed Representations.[14]
The SDRs used in HTM are binary representations of data consisting of many bits with a small percentage of the bits active (1s); a typical implementation might have 2048 columns and 64K artificial neurons where as few as 40 might be active at once. Although it may seem less efficient for the majority of bits to go "unused" in any given representation, SDRs have two major advantages over traditional dense representations. First, SDRs are tolerant of corruption and ambiguity due to the meaning of the representation being shared (distributed) across a small percentage (sparse) of active bits. In a dense representation, flipping a single bit completely changes the meaning, while in an SDR a single bit may not affect the overall meaning much. This leads to the second advantage of SDRs: because the meaning of a representation is distributed across all active bits, similarity between two representations can be used as a measure of semantic similarity in the objects they represent. That is, if two vectors in an SDR have 1s in the same position, then they are semantically similar in that attribute. The bits in SDRs have semantic meaning, and that meaning is distributed across the bits.[14]
The semantic folding theory[15] builds on these SDR properties to propose a new model for language semantics, where words are encoded into word-SDRs and the similarity between terms, sentences and texts can be calculated with simple distance measures.
Similarity to other models
Bayesian networks
Likened to a Bayesian network, an HTM comprises a collection of nodes that are arranged in a tree-shaped hierarchy. Each node in the hierarchy discovers an array of causes in the input patterns and temporal sequences it receives. A Bayesian belief revision algorithm is used to propagate feed-forward and feedback beliefs from child to parent nodes and vice versa. However, the analogy to Bayesian networks is limited, because HTMs can be self-trained (such that each node has an unambiguous family relationship), cope with time-sensitive data, and grant mechanisms for covert attention.[16]
A theory of hierarchical cortical computation based on Bayesian belief propagation was proposed earlier by Tai Sing Lee and David Mumford.[17] While HTM is mostly consistent with these ideas, it adds details about handling invariant representations in the visual cortex.[18]
Neural networks
Like any system that models details of the neocortex, HTM can be viewed as an artificial neural network. The tree-shaped hierarchy commonly used in HTMs resembles the usual topology of traditional neural networks. HTMs attempt to model cortical columns (80 to 100 neurons) and their interactions with fewer HTM "neurons". The goal of current HTMs is to capture as much of the functions of neurons and the network (as they are currently understood) within the capability of typical computers and in areas that can be made readily useful such as image processing. For example, feedback from higher levels and motor control are not attempted because it is not yet understood how to incorporate them and binary instead of variable synapses are used because they were determined to be sufficient in the current HTM capabilities.
LAMINART and similar neural networks researched by Stephen Grossberg attempt to model both the infrastructure of the cortex and the behavior of neurons in a temporal framework to explain neurophysiological and psychophysical data. However, these networks are, at present, too complex for realistic application.[19]
HTM is also related to work by Tomaso Poggio, including an approach for modeling the ventral stream of the visual cortex known as HMAX. Similarities of HTM to various AI ideas are described in the December 2005 issue of the Artificial Intelligence journal.[20]
Neocognitron
Neocognitron, a hierarchical multilayered neural network proposed by Professor Kunihiko Fukushima in 1987, is one of the first Deep Learning Neural Networks models.[21]
Deep learning
Recent connectionist-like so-called "deep learning" models are very similar to HTM, and these have similarly been linked to developmental theories of the human neocortex developed in the early 1990s by neuroscientists.[5][22]
NuPIC platform and development tools
(Links to legacy Numenta contents are broken use this to access them.)
The HTM model has been implemented in a research release of a software API called "Numenta Platform for Intelligent Computing" (NuPIC). Currently, the software is available as a free download and can be licensed for general or academic research as well as for developing commercial applications. NuPIC is written in C++ and Python.
A number of HTM software development tools have been implemented using NuPIC:
- Numenta Vision Toolkit - allows to create a customized image recognition system. It assists in collecting and preparing images for training, trains the HTM network and recognizes new images. Vision Toolkit can also optimize network training parameters by selecting one of the predefined network configurations that were found to work well with certain image types.
- Vitamin D Toolkit (discontinued) - provides a set of visual tools to inspect network configuration, find recognition problems and fine-tune network parameters.
- Numenta Prediction Toolkit (future) - is planned to include tools for simple development of general-purpose HTM networks.
Applications
The following commercial applications have been developed using NuPIC:
- Vitamin D Video – a video surveillance application that uses HTM to detect people in video by differentiating them from other moving objects.
- EDSA power analytics system[23] – an electrical power analytics, supervision and diagnostic system scheduled to be deployed in an oil field in the North Sea. It uses HTM to learn and distinguish between "routine" and "non-routine" events in an electrical power network. The system alerts an operator when a situation is not normal.
- Lockheed Martin has been using and modifying HTM technology for several applications such as integrating multiple types of sensory inputs and object recognition from geospatial imagery of an urban environment.[24]
- iResemble[25] – an iPhone application implemented using the Vision Toolkit. It has a trained HTM network that classifies a submitted photo and outputs a belief of what type of person the photo resembles.
See also
- Neocognitron
- Deep learning
- Strong AI
- Artificial consciousness
- Cognitive architecture
- On Intelligence
- Memory-prediction framework
- Belief revision
- Belief propagation
- Bionics
- List of artificial intelligence projects
- Memory Network
- Neural Turing Machine
- Multiple trace theory
Related models
References
- ↑ http://web.archive.org/web/20090527174304/http://numenta.com/for-developers/education/general-overview-htm.php
- ↑ Jeff Hawkins lecture describing cortical learning algorithms
- ↑ "New Insights from Neuroscience" (PDF). Retrieved 26 November 2012.
- ↑ http://www.numenta.com/grok_info.html
- 1 2 From Neural Networks to Deep Learning: Zeroing in on the Human Brain
- ↑ Jeff Hawkins, Sandra Blakeslee On Intelligence
- ↑ Towards a Mathematical Theory of Cortical Micro-circuits. Dileep George and Jeff Hawkins. PLoS Computational Biology 5(10)
- ↑ https://www.groksolutions.com/htm-overview/education/HTM_CorticalLearningAlgorithms.pdf
- ↑ Hinton, Geoffrey E. "Distributed representations." (1984).
- ↑ Plate, Tony. "Holographic Reduced Representations: Convolution Algebra for Compositional Distributed Representations." IJCAI. 1991.
- 1 2 Kanerva, Pentti. Sparse distributed memory. MIT press, 1988.
- ↑ Snaider, Javier, and Stan Franklin. "Integer sparse distributed memory." Twenty-fifth international flairs conference. 2012.
- ↑ Olshausen, B.A., Field, D.J., 1997, Sparse coding with an overcomplete basis set: A strategy employed by V1?, Vision Research, 37:3311-3325
- 1 2 Numenta NUPIC - Sparse Distributed representations. URL: https://github.com/numenta/nupic/wiki/Sparse-Distributed-Representations
- ↑ De Sousa Webber, Francisco (2015). "Semantic Folding Theory And its Application in Semantic Fingerprinting". arXiv:1511.08855
 [cs.AI].
[cs.AI]. - ↑ Hawkins' Blog
- ↑ Tai Sing Lee, David Mumford "Hierarchical Bayesian Inference in the Visual Cortex", 2002
- ↑ http://dileepgeorge.com/blog/?p=5
- ↑ Grossberg, S. (2007). Towards a unified theory of neocortex: Laminar cortical circuits for vision and cognition. Technical Report CAS/CNS-TR-2006-008. For Computational Neuroscience: From Neurons to Theory and Back Again, eds: Paul Cisek, Trevor Drew, John Kalaska; Elsevier, Amsterdam, pp. 79-104. http://cns.bu.edu/Profiles/Grossberg/GroCisek2007.pdf
- ↑ ScienceDirect - Artificial Intelligence, Volume 169, Issue 2, Page 103-212 (December 2005)
- ↑ Neocognitron at Scholarpedia
- ↑ J. Elman, et al. (1996) Rethinking Innateness. MIT Press.
- ↑ http://www.edsa.com/pa_articles/self_learning.php
- ↑ http://www.atl.external.lmco.com/papers/1597.pdf
- ↑ https://www.appstorehq.com/iresemble-iphone-140379/app
- ""Hierarchical Temporal Memory - Concepts, Theory, and Terminology"" (PDF). (804 KiB) by Jeff Hawkins and Dileep George, Numenta Inc., 2006-05-17
- On Intelligence; Jeff Hawkins, Sandra Blakeslee; Henry Holt, 2004; ISBN 0-312-71234-0
- Shoemaker, Phillip B., How HTMs differ from Neural networks, retrieved 2007-10-17
External links
Official
- Cortical Learning Algorithm overview (Accessed May 2013)
- HTM Cortical Learning Algorithms (PDF Sept. 2011)
- Numenta, Inc.
- HTM Cortical Learning Algorithms Archive
- Association for Computing Machinery talk from 2009 by Subutai Ahmad from Numenta
- OnIntelligence.org Forum, an Internet forum for the discussion of relevant topics, especially relevant being the Models and Simulation Topics forum.
- Hierarchical Temporal Memory (Microsoft PowerPoint presentation)
- Cortical Learning Algorithm Tutorial: CLA Basics, talk about the cortical learning algorithm (CLA) used by the HTM model on YouTube
Other
- Pattern Recognition by Hierarchical Temporal Memory by Davide Maltoni, April 13, 2011
- Vicarious Startup rooted in HTM by Dileep George
- The Gartner Fellows: Jeff Hawkins Interview by Tom Austin, Gartner, March 2, 2006
- Emerging Tech: Jeff Hawkins reinvents artificial intelligence by Debra D'Agostino and Edward H. Baker, CIO Insight, May 1, 2006
- "Putting your brain on a microchip" by Stefanie Olsen, CNET News.com, May 12, 2006
- "The Thinking Machine" by Evan Ratliff, Wired, March 2007
- Think like a human by Jeff Hawkins, IEEE Spectrum, April 2007
- Neocortex - Memory-Prediction Framework — Open Source Implementation with GNU General Public License
- Hierarchical Temporal Memory related Papers and Books