Illumina dye sequencing
Illumina dye sequencing is a technique used to determine the series of base pairs in DNA, also known as DNA sequencing. The reversible terminated chemistry concept was invented by Bruno Canard and Simon Sarfati at the Pasteur Institute in Paris.[1][2] It was developed by Shankar Balasubramanian and David Klenerman of Cambridge University,[3] who subsequently founded Solexa, a company later acquired by Illumina. This sequencing method is based on reversible dye-terminators that enable the identification of single bases as they are introduced into DNA strands. It can also be used for whole-genome and region sequencing, transcriptome analysis, metagenomics, small RNA discovery, methylation profiling, and genome-wide protein-nucleic acid interaction analysis.[4][5]
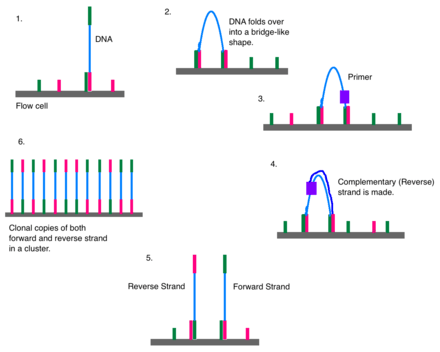
Overview
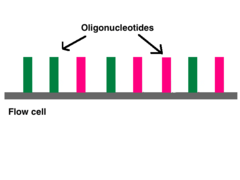
Illumina sequencing technology works in three basic steps: amplify, sequence, and analyze. The process begins with purified DNA. The DNA gets chopped up into smaller pieces and given adapters, indices, and other kinds of molecular modifications that act as reference points during amplification, sequencing, and analysis. The modified DNA is loaded onto a specialized chip where amplification and sequencing will take place. Along the bottom of the chip are hundreds of thousands of oligonucleotides (short, synthetic pieces of DNA). They are anchored to the chip and able to grab DNA fragments that have complementary sequences. Once the fragments have attached, a phase called cluster generation begins. This step makes about a thousand copies of each fragment of DNA. Next, primers and modified nucleotides enter the chip. These nucleotides have reversible 3' blockers that force the primers to add on only one nucleotide at a time as well as fluorescent tags. After each round of synthesis, a camera takes a picture of the chip. A computer determines what base was added by the wavelength of the fluorescent tag and records it for every spot on the chip. After each round, non-incorporated molecules are washed away. A chemical deblocking step is then used in the removal of the 3’ terminal blocking group and the dye in a single step. The process continues until the full DNA molecule is sequenced.[5] With this technology, thousands of places throughout the genome are sequenced at once via massive parallel sequencing.
Procedure
Tagmentation
The first step after DNA purification is tagmentation. Enzymes called transposomes randomly cut the DNA into short segments (“tags”). Adapters are added on either side of the cut points (ligation). Strands that fail to have adapters ligated are washed away.[6]
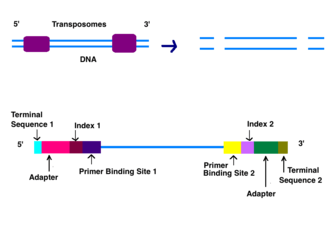
Reduced Cycle Amplification
The next step is called reduced cycle amplification. During this step, sequences for primer binding, indices, and terminal sequences are added. Indices are usually six base pairs long and are used during DNA sequence analysis to identify samples. Indices allow for up to 96 different samples to be run together. During analysis, the computer will group all reads with the same index together.[7][8] The terminal sequences are used for attaching the DNA strand to the flow cell. Illumina uses a “sequence by synthesis” approach.[8] This process takes place inside of an acrylamide-coated glass flow cell.[9] The flow cell has oligonucleotides (short nucleotide sequences) coating the bottom of the cell, and they serve to hold the DNA strands in place during sequencing. The oligos match the two kinds of terminal sequences added to the DNA during reduced cycle amplification. As the DNA enters the flow cell, one of the adapters attaches to a complementary oligo.
Bridge Amplification
Once attached, cluster generation can begin. The goal is to create hundreds of identical strands of DNA. Some will be the forward strand; the rest, the reverse. Clusters are generated through bridge amplification. Polymerases move along a strand of DNA, creating its complementary strand. The original strand is washed away, leaving only the reverse strand. At the top of the reverse strand there is an adapter sequence. The DNA strand bends and attaches to the oligo that is complementary to the top adapter sequence. Polymerases attach to the reverse strand, and its complementary strand (which is identical to the original) is made. The now double stranded DNA is denatured so that each strand can separately attach to an oligonucleotide sequence anchored to the flow cell. One will be the reverse strand; the other, the forward. This process is called bridge amplification, and it happens for thousands of clusters all over the flow cell at once.
Clonal Amplification
Over and over again, DNA strands will bend and attach to oligos. Polymerases will synthesize a new strand to create a double stranded segment, and that will be denatured so that all of the DNA strands in one area are from a single source (clonal amplification). Clonal amplification is important for quality control purposes. If a strand is found to have an odd sequence, then scientists can check the reverse strand to make sure that it has the complement of the same oddity. The forward and reverse strands act as checks to guard against artifacts. Because Illumina sequencing uses polymerases, base substitution errors have been observed,[10] especially at the 3’ end.[11] Paired end reads combined with cluster generation can confirm an error took place. The reverse and forward strands should be complementary to each other, all reverse reads should match each other, and all forward reads should match each other. If a read is not similar enough to its counterparts (with which it should be a clone), an error may have occurred. A minimum threshold of 97% similarity has been used in some labs’ analyses.[11]
Sequence by Synthesis
At the end of bridge amplification, all of the reverse strands are washed off the flow cell, leaving only forward strands. Primers attach to the forward strands and add fluorescently tagged nucleotides to the DNA strand. Only one base is added per round. A reversible terminator is on every nucleotide to prevent multiple additions in one round. Using the four-colour chemistry, each of the four bases has a unique emission, and after each round, the machine records which base was added. Starting with the launch of the NextSeq and later the MiniSeq, Illumina introduced a new two-colour sequencing chemistry. Nucleotides are distinguished by either one of two colours (red or green), no colour ("black") or binding both colours (appreading orange as a mixture between red and green).
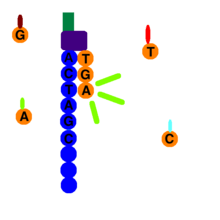
Once the DNA strand has been read, the strand that was just added is washed away. Then, the index 1 primer attaches, polymerizes the index 1 sequence, and is washed away. The strand forms a bridge again, and the 3’ end of the DNA strand attaches to an oligo on the flow cell. The index 2 primer attaches, polymerizes the sequence, and is washed away.
A polymerase sequences the complementary strand on top of the arched strand. They separate, and the 3’ end of each strand is blocked. The forward strand is washed away, and the process of sequence by synthesis repeats for the reverse strand.
Data Analysis
The sequencing occurs for millions of clusters at once, and each cluster has ~1,000 identical copies of a DNA insert.[10] The sequence data is analyzed by finding fragments with overlapping areas, called contigs, and lining them up. If a reference sequence is known, the contigs are then compared to it for variant identification.
This piecemeal process allows scientists to see the complete sequence even though an unfragmented sequence was never run; however, because Illumina read lengths are not very long [11] (HiSeq sequencing can produce read lengths around 90 bp long [7]), it can be a struggle to resolve short tandem repeat areas.[7][10] Also, if the sequence is de novo and so a reference doesn’t exist, repeated areas can cause a lot of difficulty in sequence assembly.[10] Additional difficulties include base substitutions (especially at the 3’ end of reads[11]) by inaccurate polymerases, chimeric sequences, and PCR-bias, all of which can contribute to generating an incorrect sequence.[11]
Comparison with other sequencing methods
This technique offers a number of advantages over traditional sequencing methods such as Sanger sequencing. Due to the automated nature of Illumina dye sequencing it is possible to sequence multiple strands at once and gain actual sequencing data quickly. Additionally, this method only uses DNA polymerase as opposed to multiple, expensive enzymes required by other sequencing techniques (i.e. pyrosequencing).[12]
Examples of use
Illumina sequencing has been used to research transcriptomes of the sweet potato[13] and the gymnosperm genus Taxus.[14]
References
- ↑ Canard, Bruno; Sarfati, Simon (13 Oct 1994), Novel derivatives usable for the sequencing of nucleic acids, retrieved 2016-03-09
- ↑ Canard, Bruno; Sarfati, Robert S. (1994-10-11). "DNA polymerase fluorescent substrates with reversible 3′-tags". Gene. 148 (1): 1–6. doi:10.1016/0378-1119(94)90226-7.
- ↑ http://technology.illumina.com/technology/next-generation-sequencing/solexa-technology.html
- ↑ - Sequencing Technology
- 1 2 Meyer, M.; Kircher, M. (2010). "Illumina Sequencing Library Preparation for Highly Multiplexed Target Capture and Sequencing". Cold Springs Harbor Protocols. 2010: pdb.prot5448. doi:10.1101/pdb.prot5448.
- 1 2 [<https://www.youtube.com/watch?v=womKfikWlxM> "Illumina Sequencing Technology"] Check
|url=value (help). Retrieved 24 September 2015. - 1 2 3 Feng, Y.-J., Q.-F., Chen, M.-Y., Liang, D. and Zhang, P. (2015). "Parallel tagged amplicon sequencing of relatively long PCR products using the Illumina HiSeq platform and transcriptome assembly". Molecular Ecology Resources. doi:10.1111/1755-0998.12429.
- 1 2 "Multiplexed Sequencing with the Illumina Genome Analyzer System" (PDF). Retrieved 25 September 2015.
|first1=missing|last1=in Authors list (help) - ↑ Quail, Michael A (2012). "A Tale of Three next Generation Sequencing Platforms: Comparison of Ion Torrent, Pacific Biosciences and Illumina MiSeq Sequencers.". BMC Genomics. 13: 341. doi:10.1186/1471-2164-13-341. PMC 3431227
 . PMID 22827831.
. PMID 22827831. - 1 2 3 4 Morozova, Marra O (Nov 2008). "Applications of next-generation sequencing in functional genomics". Genomics. 92 (5): 255–64. doi:10.1016/j.ygeno.2008.07.001. PMID 18703132.
- 1 2 3 4 5 Jeon, YS, Park SC, Lim J, Chun J, Kim BS (January 4, 2015). "Improved pipeline for reducing erroneous identification by 16S rRNA sequences using the Illumina MiSeq platform". Journal of Microbiology. 53 (1): 60–9. doi:10.1007/s12275-015-4601-y. PMID 25557481.
- ↑ Pettersson E., Lundeberge J., Ahmadian A. (2008). Generation of sequencing technologies. Genomics".pp. 105-111.
- ↑ Wang, Z; Fang, B; Chen, J; Zhang, X; Luo, Z; Huang, L; Chen, X; Li, Y (Dec 24, 2010). "De novo assembly and characterization of root transcriptome using Illumina paired-end sequencing and development of cSSR markers in sweet potato (Ipomoea batatas).". BMC Genomics. 11: 726. doi:10.1186/1471-2164-11-726. PMC 3016421. PMID 21182800.
- ↑ Hao, Da Cheng; Ge, GuangBo; Xiao, PeiGen; Zhang, YanYan; Yang, Ling; Ellegren, Hans (22 June 2011). "The First Insight into the Tissue Specific Taxus Transcriptome via Illumina Second Generation Sequencing". PLoS ONE. 6 (6): e21220. doi:10.1371/journal.pone.0021220.