Kanade–Lucas–Tomasi feature tracker
In computer vision, the Kanade–Lucas–Tomasi (KLT) feature tracker is an approach to feature extraction. It is proposed mainly for the purpose of dealing with the problem that traditional image registration techniques are generally costly. KLT makes use of spatial intensity information to direct the search for the position that yields the best match. It is faster than traditional techniques for examining far fewer potential matches between the images.
The registration problem
The translational image registration problem can be characterized as follows: Given two functions 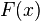 and
and 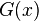 , representing values at each location
, representing values at each location 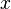 , where is a vector, in two images, respectively, we wish to find the disparity vector
, where is a vector, in two images, respectively, we wish to find the disparity vector 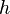 that minimizes some measure of the difference between
that minimizes some measure of the difference between 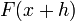 and , for in some region of interest
and , for in some region of interest 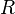 .
.
Some measures of the difference between and :
- L1 norm =
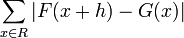
- L2 norm =
![\sqrt{\sum_{x\in R}\left [F(x+h)-G(x)\right ]^{2}}](../I/m/fdf1c7f971fd8eea434ae5a40ddc4624.png)
- Negative of normalized correlation
=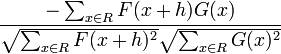
Basic description of the registration algorithm
The KLT feature tracker is based on two papers: In the first paper, Lucas and Kanade[1] developed the idea of a local search using gradients weighted by an approximation to the second derivative of the image.
One-dimensional case
If is the displacement between two images
and 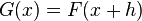 then the approximation is made that
then the approximation is made that
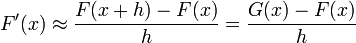
so that
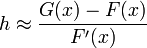
This approximation to the gradient of the image is only accurate if
the displacement of the local area between the two images to be registered
is not too large. The approximation to depends on .
For combining the various estimates of at various values of ,
it is natural to average them:
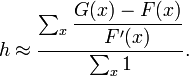
The average can be further improved by weighting the contribution of each term to it,
which is inversely proportional to an estimate of 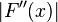 ,
where
,
where
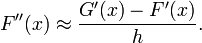
For the purpose of facilitating the expression, a weighting function is defined:
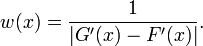
The average with weighting is thereby:
![h = \dfrac{\sum_{x}\dfrac{w(x)\left [ G(x)-F(x) \right ]}{F'(x)}}{\sum_{x}w(x)}.](../I/m/816c51837d7345153d13599b761f80ff.png)
Upon obtaining the estimate can be moved by the estimate of . The procedure is
applied repeatedly, yielding a type of Newton-Raphson iteration. The sequence of estimates will ideally converge to the
best . The iteration can be expressed by
![\begin{cases}
h_{0} = 0 \\
h_{k+1} = h_{k} + \dfrac{\sum_{x}\dfrac{w(x)\left [ G(x)-F(x+h_{k})\right ]}{F'(x+h_{k})}}{\sum_{x}w(x)}
\end{cases}](../I/m/6f5b42879555772365f5a1b88ee9880d.png)
An alternative derivation
The derivation above cannot be generalized well to two dimensions for the 2-D linear approximation occurs differently. This can be corrected by applying the linear approximation in the form:
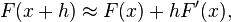
to find the which minimizes the L2 norm measure of the difference (or error) between the curves,
where the error can be expressed as:
![E=\sum_{x}\left [F(x+h)-G(x)\right ]^{2}.](../I/m/eafd9ffa549aad5a5ef0b9280d97f9d3.png)
To minimize the error with respect to , partially differentiate 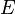 and set it to zero:
and set it to zero:
-
![\begin{align}
0 & = \dfrac{\partial E}{\partial h} \\
& \approx \dfrac{\partial}{\partial h}\sum_{x}\left [F(x)+hF'(x)-G(x)\right ]^{2} \\
& = \sum_{x}2F'(x)\left [F(x)+hF'(x)-G(x)\right ]
\end{align}](../I/m/85a704fe3c843a0882834a6ae7b38ece.png) ,
, -
![\Rightarrow h \approx \dfrac{\sum_{x} F'(x)[G(x)-F(x)]}{\sum_{x} F'(x)^{2}}\,](../I/m/f60ddc583b02b79743b8edb8685b0196.png)
This is basically the same as the 1-D case, except for the fact that the weighting function 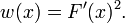 And the iteration form with weighting can be expressed as:
And the iteration form with weighting can be expressed as:
![\begin{cases}
h_0 = 0 \\
h_{k+1}=h_k + \dfrac{\sum_x w(x)F'(x+h_k) \left [G(x)-F(x+h_k)\right ]}{\sum_x w(x)F'(x+h_k)^2}
\end{cases}](../I/m/fd6b96204fab463df0c13246234d5ee4.png)
Performance
To evaluate the performance of the algorithm, we are naturally curious about under what conditions and how fast the
sequence of 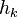 's converges to the real .
's converges to the real .
Consider the case:
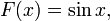
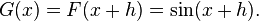
Both versions of the registration algorithm will converge to the correct for 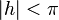 ,
i.e. for initial misregistrations as large as one-half wavelength. The range of convergence can be improved by suppressing high spatial
frequencies in the image, which could be achieved by smoothing the image, that will also undesirably suppress small details of it.
If the window of smoothing is much larger than the size of the object being matched, the object may be suppressed entirely, so that a match would be no longer possible.
,
i.e. for initial misregistrations as large as one-half wavelength. The range of convergence can be improved by suppressing high spatial
frequencies in the image, which could be achieved by smoothing the image, that will also undesirably suppress small details of it.
If the window of smoothing is much larger than the size of the object being matched, the object may be suppressed entirely, so that a match would be no longer possible.
Since lowpass-filtered images can be sampled at lower resolution with no loss of information, a coarse-to-fine strategy is adopted. A low-resolution smoothed version of the image can be used to obtain an approximate match. Applying the algorithm to higher resolution images will refine the match obtained at lower resolution.
As smoothing extends the range of convergence, the weighting function improves the accuracy of approximation, speeding up the convergence.
Without weighting, the calculated displacement 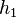 of the first iteration with
of the first iteration with 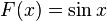 falls off to zero as
the displacement approaches one-half wavelength.
falls off to zero as
the displacement approaches one-half wavelength.
Implementation
The implementation requires the calculation of the weighted sums of the quantities 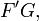
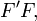 and
and
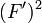 over the region of interest
over the region of interest 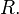 Although
Although 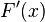 cannot be calculated exactly, it can be
estimated by:
cannot be calculated exactly, it can be
estimated by:
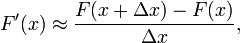
where  is chosen appropriately small.
is chosen appropriately small.
Some sophisticated technique can be used for estimating the first derivatives, but in general such techniques are equivalent
to first smoothing the function, and then taking the difference.
Generalization to multiple dimensions
The registration algorithm for 1-D and 2-D can be generalized to more dimensions. To do so, we try to minimize the L2 norm measure of error:
![E=\sum_{\mathbf{x}\in R}\left [F(\mathbf{x}+\mathbf{h})-G(\mathbf{x})\right ]^{2},](../I/m/6f9e1181f339dd38d171e2aaf93bd65a.png)
where  and
and 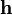 are n-dimensional row vectors.
are n-dimensional row vectors.
A linear approximation analogous:
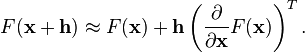
And partially differentiate with respect to :
-
![\begin{align}
0 & = \dfrac{\partial E}{\partial \mathbf{h}} \\
& \approx \dfrac{\partial}{\partial \mathbf{h}}\sum_{\mathbf{x}}\left [F(\mathbf{x})+\mathbf{h}\left(\dfrac{\partial F}{\partial \mathbf{x}}\right)^{T}-G(\mathbf{x})\right ]^{2} \\
& = \sum_{\mathbf{x}}2\left [F(\mathbf{x})+\mathbf{h}\left(\dfrac{\partial F}{\partial \mathbf{x}}\right)^{T}-G(\mathbf{x})\right ] \left(\dfrac{\partial F}{\partial \mathbf{x}}\right)
\end{align}](../I/m/3b37ee44f9acc49cc85fdd96b9788ec4.png) ,
,
![\Rightarrow \mathbf{h} \approx \left [\sum_{\mathbf{x}}\left [G(\mathbf{x})-F(\mathbf{x})\right ]\left (\dfrac{\partial F}{\partial\mathbf{x}}\right )\right ] \left [\sum_{\mathbf{x}}\left (\dfrac{\partial F}{\partial\mathbf{x}}\right )^{T}\left (\dfrac{\partial F}{\partial\mathbf{x}}\right )\right ]^{-1},](../I/m/e781d8ab8938fa81c73af0261d10ffd1.png)
which has much the same form as the 1-D version.
Further generalizations
The method can also be extended to take into account registration based on more complex transformations, such as rotation, scaling, and shearing, by considering
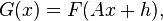
where 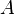 is a linear spatial transform. The error to be minimized is then
is a linear spatial transform. The error to be minimized is then
![E=\sum_{x}\left [F(Ax+h)-G(x)\right ]^2.](../I/m/c3afd0aa744d5d966450c6587b9eb264.png)
To determine the amount 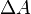 to adjust and
to adjust and 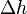 to adjust ,
again, use the linear approximation:
to adjust ,
again, use the linear approximation:
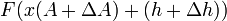
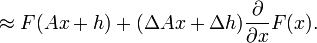
The approximation can be used similarly to find the error expression, which becomes quadratic in the quantities to be minimized with respect to. After figuring out the error expression, differentiate it with respect to the quantities to be minimized and set the results zero, yielding a set of linear equations, then solve them.
A further generalization is designed for accounting for the fact that the brightness may be different in the two views, due to the difference of the viewpoints of the cameras or to differences in the processing of the two images. Assume the difference as linear transformation:
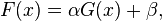
where 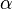 represents a contrast adjustment and
represents a contrast adjustment and 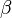 represents a brightness adjustment.
represents a brightness adjustment.
Combining this expression with the general linear transformation registration problem:
![E=\sum_{x}\left [F(Ax+h)-(\alpha G(x)+\beta)\right ]^2](../I/m/75a7a1cbbe0537e18ecd6665b8d8efee.png)
as the quantity to minimize with respect to 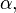
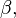
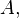 and
and 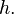
Detection and tracking of point features
In the second paper Tomasi and Kanade[2] used the same basic method for finding the registration due to the translation but improved the technique by tracking features that are suitable for the tracking algorithm. The proposed features would be selected if both the eigenvalues of the gradient matrix were larger than some threshold.
By a very similar derivation, the problem is formulated as
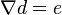
where 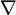 is the gradient. This is the same as the
last formula of Lucas–Kanade above.
A local patch is considered a good feature to track if both of the two eigenvalues
(
is the gradient. This is the same as the
last formula of Lucas–Kanade above.
A local patch is considered a good feature to track if both of the two eigenvalues
(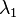 and
and 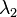 ) of
are larger than a threshold.
) of
are larger than a threshold.
A tracking method based on these two papers is generally considered a KLT tracker.
Improvements and variations
In a third paper, Shi and Tomasi[3] proposed an additional stage of verifying that features were tracked correctly.
An affine transformation is fit between the image of the currently tracked feature and its image from a non-consecutive previous frame. If the affine compensated image is too dissimilar the feature is dropped.
The reasoning is that between consecutive frames a translation is a sufficient model for tracking but due to more complex motion, perspective effects, etc. a more complex model is required when frames are further apart.
Using a similar derivation as for the KLT, Shi and Tomasi showed that the search can be performed using the formula
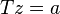
where 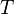 is a matrix of gradients,
is a matrix of gradients, 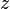 is a vector of affine coefficients and
is a vector of affine coefficients and 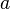 is an error vector. Compare this to
is an error vector. Compare this to 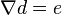 .
.
References
- ↑ Bruce D. Lucas and Takeo Kanade. An Iterative Image Registration Technique with an Application to Stereo Vision. International Joint Conference on Artificial Intelligence, pages 674–679, 1981.
- ↑ Carlo Tomasi and Takeo Kanade. Detection and Tracking of Point Features. Carnegie Mellon University Technical Report CMU-CS-91-132, April 1991.
- ↑ Jianbo Shi and Carlo Tomasi. Good Features to Track. IEEE Conference on Computer Vision and Pattern Recognition, pages 593–600, 1994.
See also
- Kanade–Tomasi features in the context of feature detection
- Lucas–Kanade method An optical flow algorithm derived from reference 1.