Kleene's algorithm
In theoretical computer science, in particular in formal language theory, Kleene's algorithm transforms a given deterministic finite automaton (DFA) into a regular expression. Together with other conversion algorithms, it establishes the equivalence of several description formats for regular languages.
Algorithm description
According to Gross and Yellen (2004),[1] the algorithm can be traced back to Kleene (1956).[2]
This description follows Hopcroft and Ullman (1979).[3] Given a deterministic finite automaton M = (Q, Σ, δ, q0, F), with Q = { q0,...,qn } its set of states, the algorithm computes
- the sets Rk
ij of all strings that take M from state qi to qj without going through any state numbered higher than k.
Here, "going through a state" means entering and leaving it, so both i and j may be higher than k, but no intermediate state may.
Each set Rk
ij is represented by a regular expression; the algorithm computes them step by step for k = -1, 0, ..., n. Since there is no state numbered higher than n, the regular expression Rn
0j represents the set of all strings that take M from its start state q0 to qj. If F = { q1,...,qf } is the set of accept states, the regular expression Rn
01 | ... | Rn
0f represents the language accepted by M.
The initial regular expressions, for k = -1, are computed as
- R-1
ij = a1 | ... | am if i≠j, where δ(qi,a1) = ... = δ(qi,am) = qj - R-1
ij = a1 | ... | am | ε, if i=j, where δ(qi,a1) = ... = δ(qi,am) = qj
After that, in each step the expressions Rk
ij are computed from the previous ones by
- Rk
ij = Rk-1
ik (Rk-1
kk)* Rk-1
kj | Rk-1
ij
Example
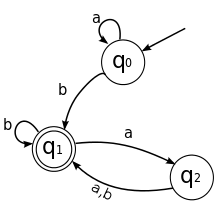
The automaton shown in the picture can be described as M = (Q, Σ, δ, q0, F) with
- the set of states Q = { q0, q1, q2 },
- the input alphabet Σ = { a, b },
- the transition function δ with δ(q0,a)=q0, δ(q0,b)=q1, δ(q1,a)=q2, δ(q1,b)=q1, δ(q2,a)=q1, and δ(q2,b)=q1,
- the start state q0, and
- set of accept states F = { q1 }.
Kleene's algorithm computes the initial regular expressions as
| R-1 00 |
= a | ε |
| R-1 01 |
= b |
| R-1 02 |
= ∅ |
| R-1 10 |
= ∅ |
| R-1 11 |
= b | ε |
| R-1 12 |
= a |
| R-1 20 |
= ∅ |
| R-1 21 |
= a | b |
| R-1 22 |
= ε |
After that, the Rk
ij are computed from the Rk-1
ij step by step for k = 0, 1, 2.
Kleene algebra equalities are used to simplify the regular expressions as much as possible.
Step 0:
| R0 00 |
= R-1 00 (R-1 00)* R-1 00 | R-1 00 |
= (a | ε) | (a | ε)* | (a | ε) | | a | ε | = a* |
| R0 01 |
= R-1 00 (R-1 00)* R-1 01 | R-1 01 |
= (a | ε) | (a | ε)* | b | | b | = a* b |
| R0 02 |
= R-1 00 (R-1 00)* R-1 02 | R-1 02 |
= (a | ε) | (a | ε)* | ∅ | | ∅ | = ∅ |
| R0 10 |
= R-1 10 (R-1 00)* R-1 00 | R-1 10 |
= ∅ | (a | ε)* | (a | ε) | | ∅ | = ∅ |
| R0 11 |
= R-1 10 (R-1 00)* R-1 01 | R-1 11 |
= ∅ | (a | ε)* | b | | b | ε | = b | ε |
| R0 12 |
= R-1 10 (R-1 00)* R-1 02 | R-1 12 |
= ∅ | (a | ε)* | ∅ | | a | = a |
| R0 20 |
= R-1 20 (R-1 00)* R-1 00 | R-1 20 |
= ∅ | (a | ε)* | (a | ε) | | ∅ | = ∅ |
| R0 21 |
= R-1 20 (R-1 00)* R-1 01 | R-1 21 |
= ∅ | (a | ε)* | b | | a | b | = a | b |
| R0 22 |
= R-1 20 (R-1 00)* R-1 02 | R-1 22 |
= ∅ | (a | ε)* | ∅ | | ε | = ε |
Step 1:
| R1 00 |
= R0 01 (R0 11)* R0 10 | R0 00 |
= a*b | (b | ε)* | ∅ | | a* | = a* |
| R1 01 |
= R0 01 (R0 11)* R0 11 | R0 01 |
= a*b | (b | ε)* | (b | ε) | | a* b | = a* b* b |
| R1 02 |
= R0 01 (R0 11)* R0 12 | R0 02 |
= a*b | (b | ε)* | a | | ∅ | = a* b* ba |
| R1 10 |
= R0 11 (R0 11)* R0 10 | R0 10 |
= (b | ε) | (b | ε)* | ∅ | | ∅ | = ∅ |
| R1 11 |
= R0 11 (R0 11)* R0 11 | R0 11 |
= (b | ε) | (b | ε)* | (b | ε) | | b | ε | = b* |
| R1 12 |
= R0 11 (R0 11)* R0 12 | R0 12 |
= (b | ε) | (b | ε)* | a | | a | = b* a |
| R1 20 |
= R0 21 (R0 11)* R0 10 | R0 20 |
= (a | b) | (b | ε)* | ∅ | | ∅ | = ∅ |
| R1 21 |
= R0 21 (R0 11)* R0 11 | R0 21 |
= (a | b) | (b | ε)* | (b | ε) | | a | b | = (a | b) b* |
| R1 22 |
= R0 21 (R0 11)* R0 12 | R0 22 |
= (a | b) | (b | ε)* | a | | ε | = (a | b) b* a | ε |
Step 2:
| R2 00 |
= R1 02 (R1 22)* R1 20 | R1 00 |
= a*b*ba | ((a|b)b*a | ε)* | ∅ | | a* | = a* |
| R2 01 |
= R1 02 (R1 22)* R1 21 | R1 01 |
= a*b*ba | ((a|b)b*a | ε)* | (a|b)b* | | a* b* b | = |
| R2 02 |
= R1 02 (R1 22)* R1 22 | R1 02 |
= a*b*ba | ((a|b)b*a | ε)* | ((a|b)b*a | ε) | | a* b* ba | = |
| R2 10 |
= R1 12 (R1 22)* R1 20 | R1 10 |
= b* a | ((a|b)b*a | ε)* | ∅ | | ∅ | = ∅ |
| R2 11 |
= R1 12 (R1 22)* R1 21 | R1 11 |
= b* a | ((a|b)b*a | ε)* | (a|b)b* | | b* | = |
| R2 12 |
= R1 12 (R1 22)* R1 22 | R1 12 |
= b* a | ((a|b)b*a | ε)* | ((a|b)b*a | ε) | | b* a | = |
| R2 20 |
= R1 22 (R1 22)* R1 20 | R1 20 |
= ((a|b)b*a | ε) | ((a|b)b*a | ε)* | ∅ | | ∅ | = ∅ |
| R2 21 |
= R1 22 (R1 22)* R1 21 | R1 21 |
= ((a|b)b*a | ε) | ((a|b)b*a | ε)* | (a|b)b* | | (a | b) b* | = |
| R2 22 |
= R1 22 (R1 22)* R1 22 | R1 22 |
= ((a|b)b*a | ε) | ((a|b)b*a | ε)* | ((a|b)b*a | ε) | | (a | b) b* a | ε | = |
((step 2 simplification to be completed))
Since q0 is the start state and q1 is the only accept state, the regular expression R2
01 denotes the set of all strings accepted by the automaton.
See also
- Floyd-Warshall algorithm — an algorithm on weighted graphs that can be implemented by Kleene's algorithm using a particular Kleene algebra
- Star height problem — what is the minimum stars' nesting depth of all regular expressions corresponding to a given DFA?
- Generalized star height problem — if a complement operator is allowed additionally in regular expressions, can the stars' nesting depth of Kleene's algorithm's output be limited to a fixed bound?
- Thompson's construction algorithm — transforms a regular expression to a finite automaton
References
- ↑ Jonathan L. Gross and Jay Yellen, ed. (2004). Handbook of Graph Theory. Discrete Mathematics and it Applications. CRC Press. ISBN 1-58488-090-2. Here: sect.2.1, remark R13 on p.65
- ↑ Kleene, Stephen C. (1956). "Representation of Events in Nerve Nets and Finite Automate" (PDF). Automata Studies, Annals of Math. Studies. Princeton Univ. Press. 34.
- ↑ John E. Hopcroft, Jeffrey D. Ullman (1979). Introduction to Automata Theory, Languages, and Computation. Addison-Wesley. ISBN 0-201-02988-X. Here: Theorem 2.4, p.33-34