Kosaraju's algorithm
In computer science, Kosaraju's algorithm (also known as the Kosaraju–Sharir algorithm) is a linear time algorithm to find the strongly connected components of a directed graph. Aho, Hopcroft and Ullman credit it to an unpublished paper from 1978 by S. Rao Kosaraju. The same algorithm was independently discovered by Micha Sharir and published by him in 1981. It makes use of the fact that the transpose graph (the same graph with the direction of every edge reversed) has exactly the same strongly connected components as the original graph.
The algorithm
The primitive graph operations that the algorithm uses are to enumerate the vertices of the graph, to store data per vertex (if not in the graph data structure itself, then in some table that can use vertices as indices), to enumerate the out-neighbours of a vertex (traverse edges in the forward direction), and to enumerate the in-neighbours of a vertex (traverse edges in the backward direction); however the last can be done without, at the price of constructing a representation of the transpose graph during the forward traversal phase. The only additional data structure needed by the algorithm is an ordered list L of graph vertices, that will grow to contain each vertex once.
If strong components are to be represented by appointing a separate root vertex for each component, and assigning to each vertex the root vertex of its component, then Kosaraju's algorithm can be stated as follows.
- For each vertex u of the graph, mark u as unvisited. Let L be empty.
- For each vertex u of the graph do Visit(u), where Visit(u) is the recursive subroutine:
- If u is unvisited then:
- Mark u as visited.
- For each out-neighbour v of u, do Visit(v).
- Prepend u to L.
- Otherwise do nothing.
- If u is unvisited then:
- For each element u of L in order, do Assign(u,u) where Assign(u,root) is the recursive subroutine:
- If u has not been assigned to a component then:
- Assign u as belonging to the component whose root is root.
- For each in-neighbour v of u, do Assign(v,root).
- Otherwise do nothing.
- If u has not been assigned to a component then:
Trivial variations are to instead assign a component number to each vertex, or to construct per-component lists of the vertices that belong to it. The unvisited/visited indication may share storage location with the final assignment of root for a vertex.
The key point of the algorithm is that during the first (forward) traversal of the graph edges, vertices are prepended to the list L in post-order relative to the search tree being explored. This means it does not matter whether a vertex v was first Visited because it appeared in the enumeration of all vertices or because it was the out-neighbour of another vertex u that got Visited; either way v will be prepended to L before u is, so if there is a forward path from u to v then u will appear before v on the final list L (unless u and v both belong to the same strong component, in which case their relative order in L is arbitrary). As given above, the algorithm for simplicity employs depth-first search, but it could just as well use breadth-first search as long as the post-order property is preserved.
The algorithm can be understood as identifying the strong component of a vertex u as the set of vertices which are reachable from u both by backwards and forwards traversal. Writing  for the set of vertices reachable from
for the set of vertices reachable from 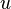 by forward traversal,
by forward traversal, 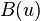 for the set of vertices reachable from by backwards traversal, and
for the set of vertices reachable from by backwards traversal, and 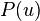 for the set of vertices which appear strictly before on the list L after phase 2 of the algorithm, the strong component containing a vertex appointed as root is
for the set of vertices which appear strictly before on the list L after phase 2 of the algorithm, the strong component containing a vertex appointed as root is
-
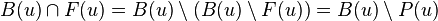 .
.
Set intersection is computationally costly, but it is logically equivalent to a double set difference, and since 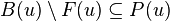 it becomes sufficient to test whether a newly encountered element of has already been assigned to a component or not.
it becomes sufficient to test whether a newly encountered element of has already been assigned to a component or not.
Complexity
Provided the graph is described using an adjacency list, Kosaraju's algorithm performs two complete traversals of the graph and so runs in Θ(V+E) (linear) time, which is asymptotically optimal because there is a matching lower bound (any algorithm must examine all vertices and edges). It is the conceptually simplest efficient algorithm, but is not as efficient in practice as Tarjan's strongly connected components algorithm and the path-based strong component algorithm, which perform only one traversal of the graph.
If the graph is represented as an adjacency matrix, the algorithm requires Ο(V2) time.
References
- Alfred V. Aho, John E. Hopcroft, Jeffrey D. Ullman. Data Structures and Algorithms. Addison-Wesley, 1983.
- Thomas H. Cormen, Charles E. Leiserson, Ronald L. Rivest, Clifford Stein. Introduction to Algorithms, 3rd edition. The MIT Press, 2009. ISBN 0-262-03384-4.
- Micha Sharir. A strong connectivity algorithm and its applications to data flow analysis. Computers and Mathematics with Applications 7(1):67–72, 1981.
External links
- A description and proof of Kosaraju's Algorithm
- Good Math, Bad Math: Computing Strongly Connected Components