Lattice sieving
Lattice sieving is a technique for finding smooth values of a bivariate polynomial 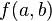 over a large region. It is almost exclusively used in conjunction with the number field sieve. The original idea of the lattice sieve came from John Pollard.[1]
over a large region. It is almost exclusively used in conjunction with the number field sieve. The original idea of the lattice sieve came from John Pollard.[1]
The algorithm implicitly involves the ideal structure of the number field of the polynomial; it takes advantage of the theorem that any prime ideal above some rational prime p can be written as ![p \mathbb Z[\alpha] + (u + v \alpha) \mathbb Z[\alpha]](../I/m/93e4c60ca04dd25448b10ba240ce4de1.png) . One then picks many prime numbers q of an appropriate size, usually just above the factor base limit, and proceeds by
. One then picks many prime numbers q of an appropriate size, usually just above the factor base limit, and proceeds by
- For each q, list the prime ideals above q by factorising the polynomial f(a,b) over
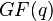
- For each of these prime ideals, which are called 'special
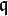 's, construct a reduced basis
's, construct a reduced basis 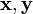 for the lattice L generated by
for the lattice L generated by 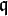 ; set a two-dimensional array called the sieve region to zero.
; set a two-dimensional array called the sieve region to zero.
- For each prime ideal
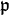 in the factor base, construct a reduced basis
in the factor base, construct a reduced basis 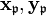 for the sublattice of L generated by
for the sublattice of L generated by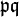
- For each element of that sublattice lying within a sufficiently large sieve region, add
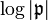 to that entry.
to that entry.
- For each element of that sublattice lying within a sufficiently large sieve region, add
- For each prime ideal
- Read out all the entries in the sieve region with a large enough value
- For each of these prime ideals, which are called 'special
- For each q, list the prime ideals above q by factorising the polynomial f(a,b) over
For the number field sieve application, it is necessary for two polynomials both to have smooth values; this is handled by running the inner loop over both polynomials, whilst the special-q can be taken from either side.
Treatments of the inmost loop
There are a number of clever approaches to implementing the inmost loop, since listing the elements of a lattice within a rectangular region efficiently is itself a non-trivial problem, and efficiently batching together updates to a sieve region in order to take advantage of cache structures is another non-trivial problem. The normal solution to the first is to have an ordering of the lattice points defined by couple of generators picked so that the decision rule which takes you from one lattice point to the next is straightforward; the normal solution to the second is to collect a series of lists of updates to sub-regions of the array smaller than the size of the level-2 cache, with the number of lists being roughly the number of lines in the L1 cache so that adding an entry to a list is generally a cache hit, and then applying the lists of updates one at a time, where each application will be a level-2 cache hit. For this to be efficient you need to be able to store a number of updates at least comparable to the size of the sieve array, so this can be quite profligate in memory usage.
References
- ↑ Arjen K. Lenstra and H. W. Lenstra, Jr. (eds.). "The development of the number field sieve". Lecture Notes in Math. (1993) 1554. Springer-Verlag.