SMART Process Acceleration Development Environment
Summary
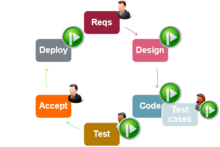
SPADE (SMART Process Acceleration Development Environment) is a software development productivity and quality tool used to create professional software in a short time and with little effort. As seen in the diagram SPADE (green icon) automates many manual activities of the Software development process. It therefore takes less time and effort to perform the full software development cycle.
With SPADE the remaining manual steps are:
- Reqs: gathering the wishes of the customer and documenting them in clear requirements, user stories or similar.
- Test cases: creating integration tests cases that will be run automatically during Test.
- Test: usability testing and testing integration with external (non-SPADE) systems.
- Accept: accepting the created solution
Automation of the other steps is possible because the (business) requirements are specified clearly by using the method SMART Requirements 2.0.[1] SPADE then uses intelligent algorithms that incorporate dependency analysis and a set of design patterns to transform these requirements to an optimized business process design, including the flow of user interactive and fully automated steps that are part of this business proces.
SPADE is a domain specific model based software development tool that is well suited for creating both complex as well as simple information processing systems. It is currently less suitable for creating software that can control hardware in real time or advanced graphical user interfaces. One can however add plug-ins for accessing functionality that is not created by SPADE.
SPADE explained in more detail
We will explain creating clear requirements using the language SMART notation[1] which is part of the method SMART Requirements 2.0[1] followed by explaining how and what SPADE will automatically create from these requirements. We will also explain creating and running test cases and the typical architecture of the software solution that is created by SPADE.
Creating clear requirements
The input of SPADE are end result oriented business requirement specifications. These explain:
| 'What' | desired result the process must produce. |
| 'When' | the desired result will be produced. In other words the condition under which it should be produced. |
| 'Where' | the information comes from. This can be an available piece of information, a calculation or a person. |
This information is placed in a document, usually a file of some sort and is written down using a formal specification language. Below is an example in gray with explanation in italic text.
Start by naming the process and its most important piece of information as its subject
Process 'Order products' with subject #('Order': ORDER)
Sum up the high level results. Double quotes are used to define requirements and help to create a result oriented break down structure.
The following applies:
"Customer has ordered products"
and
"Customer has an invoice if approved"
and
"The order needs to be approved if needed"
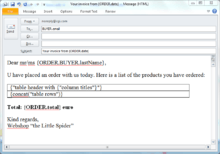
Define the requirements clearly. Use if-then-else to define 'When' results should apply or should be produced. 'Where' the information is coming from is defined using references. For instance ORDER.approved is a piece of available information that is either produced during the process or is already an available piece of information. Some requirements (results) can be specified visually. To your right the "Customer has an invoice" is specified as an e-mail.
"Customer has an invoice if approved" =
if ORDER.approved then "Customer has an invoice"
"The order needs to be approved if needed" =
if "too expensive"
then "The order needs to be approved"
else ORDER.approved = true
"too expensive" =
ORDER.total > 500
A person can also be a source of information by stating 'input from' followed by a name that identifies the role of this person or the actual user. In the example below a person with the role CONTROLLER. If this persons in turn need information to be able to give this input, you need to state that this input can be given 'based on' certain other information. In this case the date, the BUYER and the LINES of the ORDER.
"The order needs to be approved" =
ORDER.approved = input from CONTROLLER based on #(ORDER.date, ORDER.BUYER, ORDER.LINES)
The actual person that is giving the input at the time the system is used (the current user), can also be used as a piece of information. The example below defines the ORDER and its attributes. One if the attributes is called BUYER and this is filled with the actual CUSTOMER that (at the time the actual process runs) is playing that role, in other words giving the input.
"Customer has ordered products" =
One ORDER exists in ORDERS with:
date = currentDate()
BUYER = CUSTOMER
LINES = "order lines"
"order lines" =
Several LINE exist in ORDER_LINES with:
PRODUCT = input from CUSTOMER
number = input from CUSTOMER
The requirements also require a business or logical data model. Most of the logical data model can be derived from the requirements. For instance it knows which entities are needed (ORDERS, ORDER_LINES and PRODUCST) and in some cases it also can derive the type of an attribute. For instance __approved__ can only be true or false because it is used as a condition and LINES should be a relation to ORDER_LINES. Some types however cannot be derived and need to be defined explicitly in this data model. Below is an example of this data model.
ORDERS =
date : date
BUYER : USERS(1)
LINES : ORDER_LINES(*) opposite of ORDER
approved : boolean
total : decimal(10,2) = sum(LINES.total)
summary : text displayed = '{total} euro by {BUYER.firstName} {BUYER.lastName} on {date}'
ORDER_LINES =
PRODUCT : PRODUCTS(1)
number : integer
ORDER : ORDERS(1) opposite of LINES
total : decimal(10,2) = number * PRODUCT.price
PRODUCTS =
name : text
price : decimal(10,2)
summary : text displayed = '{name} ({price} euro)'
Most of this data model is pretty straight forward and resemble other data modelling techniques. Some things stand out:
- Relational attributes: relations are specified using relational attributes. For instance BUYER, which contains 1 instance in the standard entity USERS and LINES which contain multiple (*) instances of the entity ORDER_LINES and is the opposite of the relation ORDER (which is a relational attribute of the entity ORDER_LINES).
- Calculated attributes: attributes can be calculated which means they are not stored but calculated when needed. For instance the total of one instance of ORDERS is the sum of the total of its LINES. The summary is a textual value that is a template text with some placeholders inside that contain total, the first and last name of the BUYER and the date.
- Displayed: which means that if the system needs to render instances from ORDERS and it doesn't know how to do that, it will use the attribute marked with displayed.
SPADE automates design and the creation of code
SPADE perform the following steps:
- Parse: in other words read the business requirements
- Analyse dependencies: the dependencies between the different parts of the business requirements are analysed.
- Create process designs: an intelligent algorithm transform dependencies to process designs. It uses a set of design patterns and several optimization techniques to create an optimized process design that has no waste in it. The design is both a high level design (e.g. chains of business processes) as well as a low level design (e.g. at statement level).
- Generate sources: for the work flow and all the screens and steps in the process design.
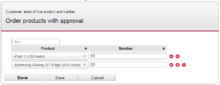
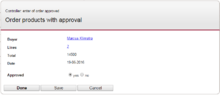
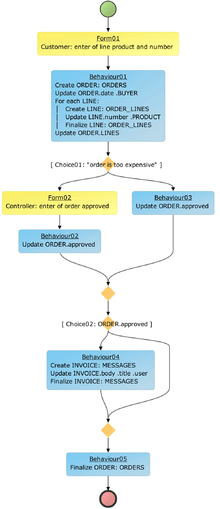
To your right is an example process design that was created by SPADE. The whole process is the business process, the yellow steps are the user interactive steps or the steps in which the system interacts with an external actor, for instance an external system. The blue steps are the fully automated steps. Example screen captures of the forms are added below the process diagram.
Creating and running test cases
When you are using the created solution, you are also recording test cases at the same time. Those test cases are then expanded with asserts that verify the outcome of the process. Below is an example in gray with explanation in italic text.
Each test scenario starts with stating which process is started by which user. In this case process 'Order products' for user 'edwinh'.
START_PROCESS = Order products, edwinh
The next part describes which roles and users will claim and then enter data in which task. In this case a customer with user name marcusk will enter 2 LINEs and each line will have a selected product and a number of products. The second task is for the manager with user name edwinh and he will fill approved with true.
# -------- FIRST CLAIM AND ENTER THE 1ST TASK ---------- task01.CLAIM_NEXT_GROUP_TASK = customer, marcusk task01.LINEs = 2 task01.LINEs[0]-c-product = 1 task01.LINEs[0]-c-number = 10 task01.LINEs[1]-c-product = 2 task01.LINEs[1]-c-number = 20 # -------- FIRST CLAIM AND ENTER THE 2ND TASK ---------- task02.CLAIM_NEXT_GROUP_TASK = manager, edwinh task02.approved = true
The next part are the asserts the check if the process achieved the predicted end result. These are not recorded and need to be added manually. In this example we have added 2 asserts. The first checks if there is +1 more instance of ORDERS with attribute approved filled with TRUE. The second checks if +2 new instances of ORDER_LINES have been added.
ASSERT_PROCESS_VALUE_COUNT_01 = ORDERS.approved = TRUE, +1 ASSERT_PROCESS_ROW_COUNT_02 = ORDER_LINES, +2
Deploying the solution
SPADE can run on its own but it often runs as an Apache Maven plugin and is therefore part of a Maven build cycle. This build cycle also includes running the test scenarios, which in turn
- deploys the generated functionality as a .jar file,
- loads tests data,
- executes the test scenario's and
- verifies the result.
The Maven build cycle can be used in daily builds all the way up to continuous delivery / deployment. For demo purposes, the steps mentioned can also be executed in the standard front-end of the resulting software solution. With the standard front end it is also possible to automate the following:
- analyze the existing database to check if the database already complies to the generated functionality;
- if there is no database present, a compliant database can be created automatically;
- if the database does not yet comply, tables and relations can be create or updated automatically.
Migrating data from an old database or from the old release to the new release is also performed automated. However, the migration software (e.g. by using SQL or ETL) is created manually.
Note that automation that SPADE provides during deployment is often used for smaller systems and for sprint demos. For deploying bigger projects, other more advanced deployment tools are more commonly used.
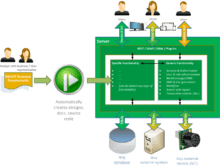
The resulting software solution
The diagram to your right shows how SPADE relates to the created solution, as well as a global architecture of this solution. Below the different elements of the diagram are explained:
- SMART Business requirements: are (manually) gathered and documented using the requirements specification language SMART notation.[1] This is a Domain-specific language that can be used to define information based end results that business or organizations would want to produce.
- Automatically creates designs, docs, source code: from the requirements SPADE then automatically creates designs, documentation and source code that can be compiled to the software solution.
- Users and GUI: the solution can interact with role based authorized users by different GUI's. The solution will already have standard GUI's for all functionality but can be expanded with Custom GUI's. GUI's of both types can be mixed if needed.
- REST/SOAP: all functionality will always have a matching REST or SOAP service that are used by the different GUI's but can also be used by authorized external systems.
- DBAL: the server also has a hibernate or similar database abstraction layer to communicate with the database.
- Plug-ins: can be used or added to the server to communicate with either external systems or with external devices. This enables solution is also able to use devices from the Internet Of Things domain. All plug-ins can be called upon from the business requirements but always in a non-technical way. For instance, if you define a DOCUMENT as a result, SPADE will know to call the plug-in associated with the entity DOCUMENTS. The plug-in will actually create and store a physical document.
- Specific functionality: this is the functionality that is created based upon the business requirements. With it you can create a wide variety of functionality. SPADE users can use a library of off-the-shelf requirements for example CRM, HR, profile matching and financial functionality. This can be inserted and adjusted to fit the specific needs of the client. The specific functionality can use all plug-ins as well as all generic functionality to extend the domain of available functionality.
- Generic functionality: by default, the solution is already equipped with a lot of standard generic functionality. For instance DMS, document generation, auto e-mails, SMS, messaging, advanced search, browse through data and export.
Which software development activities are automated and which are manual?
The next table shows which software development activities are automated by SPADE and which exceptions apply.
| Software development activity | Manual or Automated | Exceptions |
|---|---|---|
| Requirements | Manual | n.a. |
| Design | Automated | Designs for incoming interfaces to external systems and complex or fancy graphical user interfaces need to be created manually. |
| Coding / programming | Automated | parts that are designed manually |
| Testing preparation | Manual | n.a. |
| Performing tests | Automated | smoke tests for first releases and testing the user interfaces should be performed manually. |
| Deployment | Automated | creating the data migration is often done manually. As mentioned above, other deployments tools and techniques are often used for larger systems. Configuring these is also done manually. |
| Documentation | Automated | The designs and the generated source are documented automatically. This is often complimented with a small amount of manually created documentation. |
History
- 2000: in 2000 Edwin Hendriks of the company CMG (company) (now part of CGI Group) developed a process improvement method called Process Acceleration. At the core of this method was a way to define the desired end result of a business process fully unambiguous as well as a structured approach to deduce the most optimal business process that would achieve this end result. This was the birth of the first version of SMART notation[1] (at that time called PA notation) which is a formal language that can be used to specify end results of entire process chains (versus specifying the process chain itself). CMG (company) used this method and SMART notation[1] for several of their projects and their clients.
- 2007: although successful, CMG (company) at that time was not known for delivering process improvement consultancy. That was the reason for CMG (company) (at that time merged with Logica) to focus on the core of Process Acceleration, thus resulting in 2007 in a method that improves software development called PA SMART Requirements (now called SMART Requirements 2.0[1]). Since that time SMART Requirements 2.0[1] has been used by CGI Group and their customers as well as other companies and organizations.
- 2008: having a unambiguous definition of the end result of a process chain, and having a structured approach to deduce the most optimal process from this end result, sprung the idea to create a tool that could read the end result, deduce the most optimal process from it, and generate the software for each step in the process. Edwin Hendriks, Marcus Klimstra and Niels Bergsma developed a first working prototype of the SPADE (at that time called the PA Generator) using [.NET] and also producing systems using a [.NET] architecture.
- 2010: Logica decided to start the development of a commercial usable version of the SPADE.
- 2011: version 2.12 of the SPADE was used to create the first 2 systems that were made operational. Being a cross departmental time tracking system and an anonymous voting system both used by Logica itself.
- 2012: version 3 of the SPADE was created. This was the first commercial usable version of the SPADE. From that time SPADE was used to create solutions for the clients. It was often used to recreate existing legacy systems because of the short time and cost associated when creating solutions using SPADE. Despite the increased development speed and low costs, SPADE still had teething problems. This made it difficult to estimate the actual time needed to (re)create solutions making it hard to plan projects. This was the same year that Logica was acquired by CGI Group.
- 2015: version 4 of SPADE was used for the first time by elementary school children to create an exam system. It showed that creating SMART requirements and then asking SPADE to create a professional system for them was relatively easy when compared to other ways of creating software. In the same year a small rocket was launched which interacted with SPADE created ground station software. It showed that SPADE could in fact interact with external devices pretty fast (but still not yet fast enough to be usable to create real-time systems).
- 2016: in version 4.4 SPADE most teething problems were solved making it possible to (re)create large and complex systems in a short time. SPADE is currently being expanded to provide an easier way to create and change requirements as well as an easier way to customize the standard GUI. This will make it possible for more non-developers to use SPADE to create solutions.
Advantages, disadvantages and considerations
On the upside SPADE shows remarkable development speeds. International benchmarks show that the complete development cycle will be completed on average 20 times faster when compared to conventional techniques and in many cases it is even faster to completely recreate the functionality of existing software solutions compared to buying and configuring them. This development speed of course makes it easier for clients to see and try out the newly created solution. Of course by automating design and coding there will be almost no design and coding errors. The fact that the resulting solutions has no vendor-lock and is completely based on free to use open source components is also a big plus. Of course SPADE is also easy to learn.
On the downside SPADE will remains a domain specific language and will therefore not be suitable for any type of functionality. This will require conventional development or other tools. Besides this real-time performance and the ability to change the GUI more easily is something that needs extra development. SPADE is also rather new and is not yet considered a mainstream development tool. Of course creating SMART requirements takes more effort and skill compared to just describing them in a couple of sentences.
One should always consider that in normal software development the requirements define a fixed "contract" of the functionality that should be created. For instance the user story in a Scrum development team should also be fixed before the user story can be developed during a sprint. This is the same for SPADE projects. However when the requirements or the user stories are ready to be developed, the sprint will be performed by SPADE and this will take only a couple of minutes. This has resulted in the tendency to move the requirements phase (the creation of the user stories) to the sprint. This is therefore considered to be a bad practice in both normal Agile development as well as Agile development using SPADE.
Another consideration is that it is so easy to large and complex functionality. Although this poses no problem for SPADE, it does make it hard for certain people to handle the sheer size and complexity of the functionality of system. It is therefore advisable to still tackle size and complexity in the same way as you would in normal system development. By chopping up and structuring functionality in comprehensible pieces.
See also
References
External links
| Wikimedia Commons has media related to SMART Process Acceleration Development Environment. |
Category:Agile software development