Sub-band coding
In signal processing, sub-band coding (SBC) is any form of transform coding that breaks a signal into a number of different frequency bands, typically by using a fast Fourier transform, and encodes each one independently. This decomposition is often the first step in data compression for audio and video signals.
SBC is the core technique used in many popular lossy audio compression algorithms including MP3.
Basic principles
The utility of SBC is perhaps best illustrated with a specific example. When used for audio compression, SBC exploits auditory masking in the human auditory system. Human ears are normally sensitive to a wide range of frequencies, but when a sufficiently loud signal is present at one frequency, the ear will not hear weaker signals at nearby frequencies. We say that the louder signal masks the softer ones. The louder signal is called the masker, and the point at which masking occurs is known as the masking threshold.
The basic idea of SBC is to enable a data reduction by discarding information about frequencies which are masked. The result differs from the original signal, but if the discarded information is chosen carefully, the difference will not be noticeable, or more importantly, objectionable.
Encoding audio signals
The simplest way to digitally encode audio signals is pulse-code modulation (PCM), which is used on audio CDs, DAT recordings, and so on. Digitization transforms continuous signals into discrete ones by sampling a signal's amplitude at uniform intervals and rounding to the nearest value representable with the available number of bits. This process is fundamentally inexact, and involves two errors: discretization error, from sampling at intervals, and quantization error, from rounding.
The more bits used to represent each sample, the finer the granularity in the digital representation, and thus the smaller the error. Such quantization errors may be thought of as a type of noise, because they are effectively the difference between the original source and its binary representation. With PCM, the only way to mitigate the audible effects of these errors is to use enough bits to ensure that the noise is low enough to be masked either by the signal itself or by other sources of noise. A high quality signal is possible, but at the cost of a high bitrate (e.g., over 700 kbit/s for one channel of CD audio). In effect, many bits are wasted in encoding masked portions of the signal because PCM makes no assumptions about how the human ear hears.
More clever ways of digitizing an audio signal can reduce that waste by exploiting known characteristics of the auditory system. A classic method is nonlinear PCM, such as mu-law encoding (named after a perceptual curve in auditory perception research). Small signals are digitized with finer granularity than are large ones; the effect is to add noise that is proportional to the signal strength. Sun's Au file format for sound is a popular example of mu-law encoding. Using 8-bit mu-law encoding would cut the per-channel bitrate of CD audio down to about 350 kbit/s, or about half the standard rate. Because this simple method only minimally exploits masking effects, it produces results that are often audibly poorer than the original.
Sub-band coding is used for example in the G.722 codec. It uses sub-band adaptive differential pulse code modulation (SB-ADPCM) within a bit rate of 64 kbit/s. In the SB-ADPCM technique, the frequency band is split into two sub-bands (higher and lower) and the signals in each sub-band are encoded using ADPCM.
A basic SBC scheme
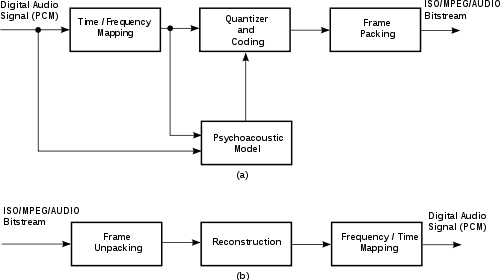
To enable higher quality compression, one may use subband coding. First, a digital filter bank divides the input signal spectrum into some number (e.g., 32) of subbands. The psychoacoustic model looks at the energy in each of these subbands, as well as in the original signal, and computes masking thresholds using psychoacoustic information. Each of the subband samples is quantized and encoded so as to keep the quantization noise below the dynamically computed masking threshold. The final step is to format all these quantized samples into groups of data called frames, to facilitate eventual playback by a decoder.
Decoding is much easier than encoding, since no psychoacoustic model is involved. The frames are unpacked, subband samples are decoded, and a frequency-time mapping reconstructs an output audio signal.
Beginning in the late 1980s, a standardization body called the Motion Picture Experts Group (MPEG) developed generic standards for coding of both audio and video. Subband coding resides at the heart of the popular MP3 format (more properly known as MPEG-1 Audio Layer III), for example.
References
This article is based on material taken from the Free On-line Dictionary of Computing prior to 1 November 2008 and incorporated under the "relicensing" terms of the GFDL, version 1.3 or later.
External links
Data compression methods | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Lossless |
| ||||||||||
| Audio |
| ||||||||||
| Image |
| ||||||||||
| Video |
| ||||||||||
| Theory | |||||||||||
| |||||||||||